VIDEO
Eva Condron-Wells (Xilinx Senior HR Manager) warmly welcomed the crowd of close to a hundred girl geeks gathered at Xilinx’s San Jose headquarters for dinner, demos, networking and talks on March 12, 2019. “Lightning Talks” were led by Niyati Shah (Xilinx Senior Engineer) on Compilers for adaptable compute acceleration, Changyi Su (Xilinx Staff Engineer) on machine learning platforms, and Uma Madhugiri (Xilinx Senior Engineer) on real-time video transcoding. The final portion of the talk was executive panel discussion on Accelerating Computation for Real-Time Machine Learning featuring: Jayashree Rangarajan (Xilinx Senior Director, Software Development), Jennifer Wong (Xilinx Vice President, FPGA Product Development), Ambs Kesavan (Xilinx Senior Director, Software Infrastructure Engineering & DevOps), Lori Pouquette (Xilinx Vice President, Global Customer Operations) and Tom Wurtz as the panel moderator.
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- See open jobs at Xilinx and check out open jobs at our trusted partner companies.
- Find more Xilinx Girl Geek Dinner photos from the event – please tag yourselves!
- Does your company want to sponsor a Girl Geek Dinner in 2021? Talk to us!
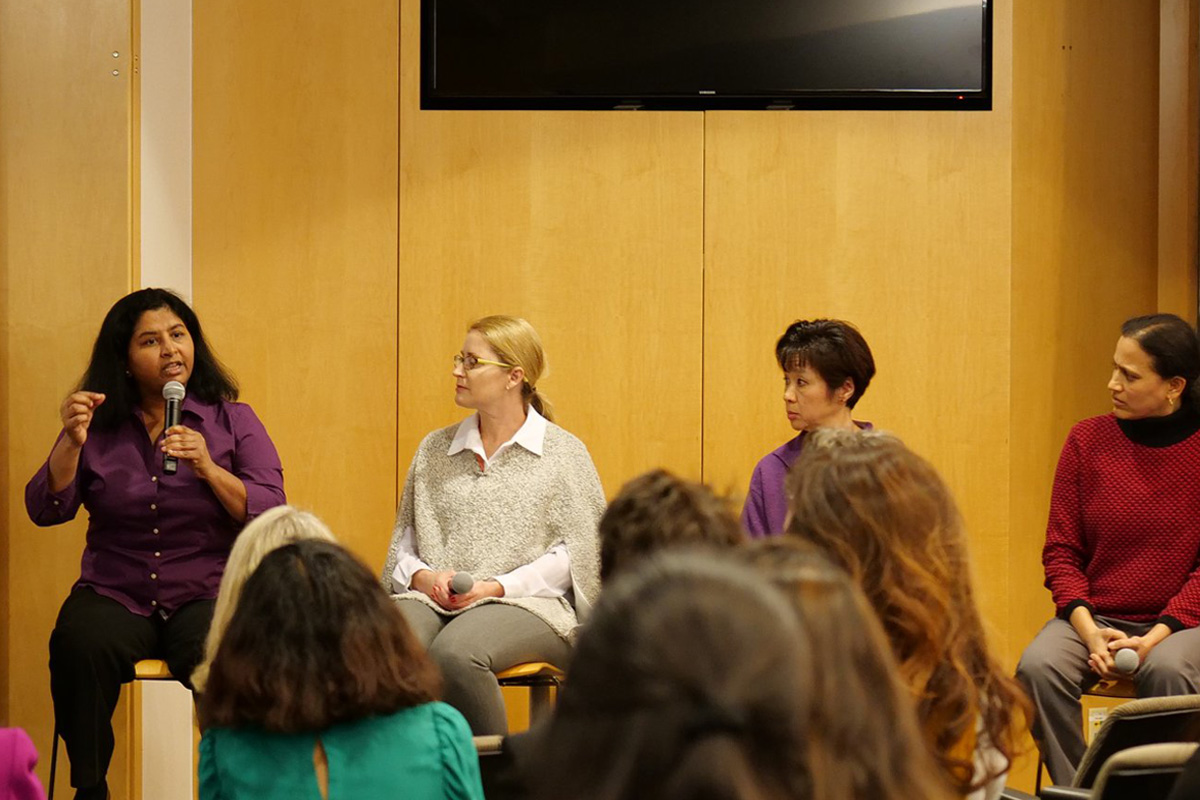
Xilinx girl geeks: Jayashree Rangarajan, Lori Pouquette, Jennifer Wong and Ambs Kesavan discuss the latest trends in accelerating computation for real-time machine learning at Xilinx Girl Geek Dinner in San Jose, California.
Speakers:
Eva Condron-Wells / Senior Manager of Talent Development / Xilinx
Niyati Shah / Senior Software Engineer / Xilinx
Changyi Su / Staff Design Engineer / Xilinx
Uma Madhugiri Dayananda / Senior Software Engineer / Xilinx
Tom Wurtz / Senior Director, Documentation & Program Management / Xilinx
Ambs Kesavan / Senior Director, Software Infrastructure Engineering & DevOps / Xilinx
Lori Pouquette / VP, Global Customer Operations / Xilinx
Jayashree Rangarajan / Senior Director, Software Development / Xilinx
Jennifer Wong / VP, FPGA Product Development / Xilinx
Angie Chang / CEO & Founder / Girl Geek X
Transcript of Xilinx Girl Geek Dinner – Lightning Talks & Panel:
Angie Chang: Okay. Here I go. Hi, thanks to you all for coming to Xilinx. My name is Angie Chang and I’m the founder of Girl Geek X. How many of you here, it’s your first Girl Geek Dinner? Okay. A good amount. All right, so Girl Geeks Dinners have been happening up and down the San Francisco Bay Area for the last 10 years. About every week, we’re in a different company. And I’m really excited to be here tonight at Xilinx.
Angie Chang: Personally, I was really excited when I looked up the website and I was like “I can’t wait to come here, check out the technology”. And the demos have been really awesome, and I encourage you to hangout and look at them. And walking down that hall of patents is very inspiring. And of course the food was amazing.
Angie Chang: So, thank you to everyone for coming. One thing I want to encourage everyone who comes to Girl Geek Dinner is to network. And I know that’s a kind of scary term, we’re always told to network. But one thing that I always try to do, even as an introvert, is to meet people. At least one or two people over a dinner, when you guys are chewing your food, just talk to people, ask them what they’re doing, if there’s anything you could do for them, and if there’s anything they could do for you. Because people are often looking for new opportunities, they’re looking to learn about the technology and also just to make friends.
Angie Chang: ‘Cause when you have friends in your workplace, or in your industry, that’s how we can stay in tech. We all know that women are dropping out of the workforce over time, and that’s really why we continue to do these dinners, is to encourage woman to continue coming out, meeting each other, encourage each other, and helping each other stay leaning in or whatever you like to call it, to your career.
Angie Chang: So please enjoy yourselves, and thank you again, Xilinx, for hosting.

Senior Manager of Talent Development Eva Condron-Wells welcomes the crowd to Xilinx Girl Geek Dinner in San Jose, California.
Eva Condron-Wells: Wonderful, thank you so much, Angie.
Eva Condron-Wells: So welcome to Xilinx. My name is Eva Condron-Wells and am a senior manager in human resources. I have the pleasure of helping employees at Xilinx listen, give, and feel as though they belong.
Eva Condron-Wells: I’m a social scientist by background, and I grew up in this very specific niche of the semiconductor industry, at another well known company. Most of my career has been in this particular slice of the semiconductor industry. And I think, in this moment, I just want to reflect on the fact that we have many things to be grateful for. And I want to start this evening with thanking a number of people.
Eva Condron-Wells: So first and foremost, thank you to the Girl Geek team for creating this type of forum for us to connect. So thank you so much, Girl Geek. Thank you to our Xilinx greeters, gurus, and guides. I hope that they’re making your visit meaningful. If you haven’t already seen other aspects of our campus, we welcome you to join us in the demo room later on. And, of course our guests, right? So you took time out of your day to come meet us, we know that you work hard and we’re all different types of Girl Geeks, but regardless of that difference, we’re here together to celebrate that brilliance of who you are and share who we are. So thank you for taking time out of your busy days to join us.
Eva Condron-Wells: And speaking of Xilinx, how many of you knew what Xilinx is or does before you saw the Girl Geek invitation? Raise your hands.
Eva Condron-Wells: Wow, that’s pretty impressive. You must be in fairly technical households. Because Xilinx, sometimes called X-links, but we help people understand how to pronounce it, isn’t necessarily a household name. That said, we affect the lives of people everyday. As we’re nested in technology that’s used broadly around the world, affecting everyone’s lives.
Eva Condron-Wells: Xilinx is a 35 year old company. Founded, what I like to say, on friendship. It was founded on friendship and a very incredible idea that is continuing to create many innovations, now and in the future. Our mission is to build the adaptable intelligent world. We have 4,000 employees plus, worldwide, and 4,000 plus patents. Giving us a one-to-one ratio of people to patents.
Eva Condron-Wells: When I articulate the pride I have in where I work, and who I work with, I genuinely mean we have some of the most brilliant people in the world. And you will get to hear from some of them tonight.
Eva Condron-Wells: So we invented the field programmable gate array. Not something everyone hears everyday, but this is a device that makes the life of an engineer easier. It speeds up their ability to perform their responsibilities and have chips work in various ways, right, thousands of applications can be used. But these engineers are empowered to reprogram chips in the field in hours instead of waiting weeks to get a completely new product. So this is the power of what we were founded on, the concept of enablement, empowerment, and acceleration.
Eva Condron-Wells: We have over 60 industry firsts, and our latest product, Alvio… Which is absolutely gorgeous, and is in our demo room, you can see the board… Is plugged into data centers, giving a 90x acceleration over a CPU. This nested technology is inside of thousands of products, changing the way we live, love, work, and play.
Eva Condron-Wells: We are not only diverse in our thought, that creates this technology, we are seekers of innovation, and we welcome brilliant minds who want to play in this space as well.
Eva Condron-Wells: Tonight our focus is on acceleration. You will gain insights into acceleration by the people who enable it. We will have three lightning talks, a panel, and Q&A where we look forward to hearing your questions to dive a little bit deeper into this topic. After 8 pm, we’ll transition to desert for those of you who haven’t already taken advantage of that. Some more demos, just around the corner, and some more networking.
Eva Condron-Wells: This is a very special evening for us, and we’re thrilled to have you. Now onto acceleration. Let’s let the lightning talks being. May I have our first presenter? So please welcome one of our first of three presenters, Niyati Shah. Thank you so much, Niyati.

Senior Software Engineer Niyati Shah gives a talk on compilers for adaptable compute acceleration at Xilinx Girl Geek Dinner.
Niyati Shah: Good evening, everyone. So let me begin my introducing myself. My name is Niyati and I work in the logic optimization group. I primarily focus on software architecture and [inaudible] design. Outside of work, I enjoy weightlifting, and traveling, and doing what I love, both at work and outside is what makes me a girl geek.
Niyati Shah: So let me start by asking you all a question. How many of you here are hardware engineers? Brilliant. And how many are software engineers? Perfect.
Niyati Shah: So, as we can see right in this room, we have a range of distribution of engineers from hardware background and software background. And that, I believe, presents the direction in which Xilinx has been headed. Traditionally Xilinx is a semiconductor and FPG chip company, and most of our customers used to be hardware developers. But as we are moved into the data center and acceleration markets, more of our customers are coming from software backgrounds.
Niyati Shah: And, what I’d like to do today, is give you an overview of the tools that we have that help our developers, regardless of their background, use our FPS to run their designs.
Niyati Shah: So we have the Hardware Developers who code using RTL, Verilog, VHDL. And for them, we have our signature product, which is the Vivado Design Suite. Next we have our Hardware Aware System Software Developers, who use C/C++ and SystemC. And for them, we provide them the Vivado HLS Compiler. We also have our Software Application Developers, who tend to use FPS mostly for accelerating their products or their designs. And for them, we have the SDAccel environment. And finally, for our Data Scientists who use frameworks such Caffe and TensorFlow, we have the AI Compilers or Edge Compilers.
Niyati Shah: In the next few slides, I’m going to go into a little bit more detail onto each of these different tools, so that you can get an idea of how they meet the needs of the targeted developers.
Niyati Shah: So as I mentioned, most of our hardware engineers work with RTL, Verilog, VHDL. But their figure is a piece of hardware, and it’s only going to understand binary numbers or bitstream. And so we have to take the RTL through a process to generate that bitstream. And the best analogy that I could give is kind of a translator. So, if you and your neighbor were to speak in, say, different languages, and the translator will go from your language and convert it to a language that your neighbor can understand. And so we take the RTL through a similar process. We start with synthesis. But [inaudible] the RTL, we apply synthesis. And the job of synthesis is to create a logical netlist , which is technology mapped to the targeted FPGA.
Niyati Shah: Once that is complete, then we need to optimize the netlist. And that’s where I come in. My team and I work on optimizing the logical netlist. We’ve optimized the design for power, area, timing, depending on the developer need. And finally create an optimized netlist, which will better use the resources that are on the FPGA.
Niyati Shah: Once that part is complete, we run placement. And the placement essentially takes these logical blocks here, and puts them on physical locations on the FPGA. Finally, we have the router which connects those physical blocks together. And after placement and routing are complete, we have a bitstream that we load on the FPGA to run the design.
Niyati Shah: Now, instead of starting an RTL, if our developers were to start with say, C/C++ or SystemC, then an additional step gets added because we have to first convert those languages to RTL before they can be fed into the backend tools.
Niyati Shah: And that’s where our Vivado HLS Compiler steps in. The HLS Compiler provides an eclipse ID, and allows our customers to design and develop using our product… The Vivado HLS Compiler and be part of this setting on top of the Vivado Design Suite. So, once the C/C++ is converted into RTL then we feed it into the Vivado Design Suite and generate a bitstream. And that allows us to provide a comprehensive solution for people starting with C/C++ or SystemC.
Niyati Shah: Now so far the tools I have talked about address the needs of our hardware developers. But for our software application developers, we also have a tool, which is our SDAccel Environment. The SDAccel Environment and Compiler sits on top of the existing Vivado HLS Compiler and the Vivado Design Suite, and allow users with no FPGA background, no hardware expertise, to take their designs and run them on our FPGAs. They will also allow us to support heterogeneous applications. So most of our software application developers are trying to accelerate their designs using the FPGAs. And so the designs will have a software component and they will have a hardware component. And the best example I can give you, is that of computer vision.
Niyati Shah: So I’m sure some of you have security cameras at home. And, in that case, you know that there are multiple parts to that. There is recording live video, but there is also object detection, where it will tell you there’s your dog is running around outside, or say there’s a robber in your house. And in that case, the object detection part is what gets accelerated using hardware.
Niyati Shah: The SDAccel Environment provides multiple different tools to our customers. We have a debugger, profiler, libraries ranging all the the way from low level mat libraries to high performing DSP libraries, but the star of the show is the compiler. The compiler helps us provide a comprehensive solution for both the software parts and for the hardware parts. The compiler compiles the software part so that it can be ran on the x86 machine. And it compiles all the individual hardware components, the kernels, so that they can go onto the FPGA. The kernels are compiled using the xocc compiler, which internally leverages the Vivado HLS Compiler and the Vivado Design Suite to generate bitstream for the parts that need to be accelerated.
Niyati Shah: So once the compilation is complete, then the software part will run on the [inaudible] machine, whereas the hardware part, which are the kernels, will run on the FPGA and they will communicate with used each of their using Xilinx runtime tools.
Niyati Shah: Now this SDAccel Environment and compilers are very crucial and critical building blocks in our next set of compilers, which are aimed towards our data scientists, who provide us models and frameworks such as Caffe and TensorFlow.
Niyati Shah: Our AI Compilers… The object here is to take the models that the customers have provided and optimize them with Deep Neural Network pruning and quantization, so that we can get optimized models. And these optimized models are then targeted using our SDAccel Compiler, so that they can go into the FPGA and generate a bitstream. Finally, we have our SDI Compilers, which provides bitten interfaces. And so we can integrate very easily with the Caffe and TensorFlow families.
Niyati Shah: What I would like to leave you with is that regardless of your background, whether it be software, hardware, or anything between, we at Xilinx have a tool that will allow you to take your design and run it on our FPGAs easily and efficiently. Thank you.
Eva Condron-Wells: Thank you. Our next presenter is Changyi Su.

Staff Design Engineer Changyi Su gives a talk on machine learning platforms at Xiliinx Girl Geek Dinner.
Changyi Su: Thank you for your introduction. My name is Changyi Su. I’m a design engineer from the device power and signaling technology team. My job is focusing on memory interface, timing analysis, and where a [inaudible].
Changyi Su: So today, I will go over one aspect of machine learning, the memory. So I will explain why memory is one of the enabler for machine learning and how Xilinx can be part of the solutions.
Changyi Su: We know that deep learning is one of the many approaches of machine learning, which try to simulate the human brain working with neurons. The neural network has a layered structure, each of the layers, the dot, simulate the neuron. The line between the nodes is a wait. So all the neuron network does is a computation. To compute the output of each of the node by multiplying the wait and the each of the input nodes, and then plug into the activation function. So as shown in this figure, compared to other machine learning algorithms, deep learning algorithms scale up much better with small data. Therefore, the performance of deep learning algorithm is limited by the need for a better hardware acceleration for scaling up data size and algorithm size.
Changyi Su: Recently, FPGA become a very strong competitor to GPUs, to serve as well based accelerator for machine learning. So with a programmable, flexible, how well configuration FPGA often provide better performance per watt to GPUs. Xilinx FPGAs support many types of memory technologies, either internal or external to the device. Compared to the off-chip memory, the on-chip memory has lower latency, lower power consumption, but a higher data bandwidth. FPGA devices offer the industrial leading 500 megabit on-chip memory storage space. So this allow the users to create on-chip memory of real size to suit their applications and also eliminate some of the external components. However, the on-chip memory is very expensive, and hard to expand the capacity. Therefore, the hardware accelerators still have to depend the external memory to meet the storage requirement for machine learning. And also the bandwidth of the off-chip memory is a bottleneck.
Changyi Su: So, with Xilinx’s devices, engineers are able to optimize the memory solution for different applications. For example, for machine learning, the intermediate data… Activation data is usually stored in on-chip memory, to reduce the data movement between the processor and the off-chip memory. The HBM and DDR can be used to store the input data in a right [inaudible], the way to write a parameters.
Changyi Su: So, when we’re working on the memory solution, one big challenge is the trade off between the memory and the computer resources, to achieve the best performance with the lowest latency and lowest power consumption. So, this is a most amazing part of my job in Xilinx. And this makes me a Girl Geek.
Changyi Su: As I mentioned in the previous slide, due to the capacity limitation on-chip memory, how the accelerator still have to rely on external memory to provide the massive storage for machine learning. So over the years, the DRAM Chip density is scaling up. Therefore, the DDR memory capacity upgrade is one of the easiest way to immediately improve the system performance. So we can increase the memory density by using high density DRAM chips, or multiple die package of DRAM chips. Also, the dual in-line memory model–DIMM–is very effective to increase memory capacity with minimum PCP space. So also, DIMM is a model which can turn several DRAM chips on one side or both side of a small circuit board. DIMM can be also config to a multiple RAM configuration to further increase memory capacity. However, with multiple loading, the signal integrity of the memory channel is severely degraded. So the entire system may not operate reliably at higher data rates. Fortunately, most of this can be solved by optimizing the channel configuration with the efforts and expertise from memory design system engineers.
Changyi Su: Over the past 10 years, the DDR memory data bandwidth capability did not evolve quickly enough to keep pace with the bandwidth demanding from applications such as machine learning, video transcoding. So to bridge the bandwidth gap, Xilinx introduce high bandwidth memory, HBM. HBM take advantage of circuit stacking technology that puts FPGA, DRAM, side by side in the same package. So, the whole package DRAM structure together with one thousand data bandwidth, HBM not only can provide extra more storage space, but also enable terabyte per second data bandwidth. So with HBM enabled FPGA devices, fewer DDR components are needed. For some extreme case, like this example, without any external memory components, Xilinx’s HBM solution can provide the same capacity, but much higher data bandwidth, and the better power efficiency.
Changyi Su: So the takeaway of my presentation today is evolving machine learning workloads demand varying bandwidth requirements. Xilinx’s diverse memory technologies enable it. Thank you.
Eva Condron-Wells: Thank you Changyi. And our next speaker and final lightening talk presenter is Uma Madhugiri Dayananda.

Senior Software Engineer Uma Madhugiri Dayananda gives a talk on real time video transcoding at Xilinx Girl Geek Dinner.
Uma Madhugiri Dayananda: Hello, everyone. Today we’re going to explore how real time transcoding can be accelerated on FPGA in the context of data center. Can you guys take a guess on what kinds of media applications these are?
Uma Madhugiri Dayananda: Sorry?
Audience Member: Facebook.
Uma Madhugiri Dayananda: Yeah. Any others?
Uma Madhugiri Dayananda: So, that’s Facebook Live and Twitch Live Streaming, that’s used for gaming.
Uma Madhugiri Dayananda: And, it’s just not these two applications, you also have YouTube Live, and LinkedIn just announced their live streaming application this couple of weeks ago. And it’s not just limited to these applications, live video is just everywhere and it’s growing rapidly.
Uma Madhugiri Dayananda: What’s happening behind these live videos? We have a huge distribution of clients here for example, our cellphones, the tablets, the PC, the TVs, are connected all via wireless networks and each of them have their own resolution and network characteristics. And we want to download the live video to each of these clients, so… To download the live video to each of these clients, the live video input is pre-encoded with the HEVC Encoder, at a different resolution and a bitrate of… And using video transcoding. So, essentially video transcoding is the conversion of one video encoding format into another.
Uma Madhugiri Dayananda: What is the advantage of video transcoding? It provides savings in terms of bandwidth and storage [inaudible]. So how many of you have seen live videos then? You experienced video stars by watching live video? Video consumes a lot of processing resources and power, and for live video applications, latencies involves milliseconds, so…
Uma Madhugiri Dayananda: Here’s a plot that shows the encoder quality preset versus the performance. I’m taking a specific example of x265 preset slow, with the quality preset on it’s supposed to be very good, like when you look at it visually. So, comparing that… If it’s encoded with CPU, you get 10 frames per second, but if the same application is being run on FPGA it’s like 120 frames per second. And for data centered context, it’s not just the quality and performance, you also have to consider the power as well. So considering all the three in the equation, you can see that it is like 72x acceleration.
Uma Madhugiri Dayananda: How does the FPGA solution compare to GPU solution? So here is an example of FPGA based HEVC Encoder compared against NVIDIA GPU. HEVC Encoder and see at the same quality level there’s 35% bitrate savings. Which translates into your bandwidth and streaming cost reduction.
Uma Madhugiri Dayananda: Another reason for using FPGA is probably your transcoding. So the video codec world is changing with the introduction of new codecs every few years. If you the timeline, from 2010 to 2020, there’s four new codecs. We already have HEVC and VP9, and AV1 was just standardized last year, and VVC is going to be standardized next year, so… You have a hardware or a custom chip for each of these codec, if you have that then it’s going to be a lengthy design process and also you can’t use the hardware, so… If you use FPGA, then the applications can be adapted… On the same FPGA you have HEVC application be running and also the VP9 application, so FPGAs are adaptable and reusable.
Uma Madhugiri Dayananda: What is happening behind the scenes? How is the video transcoding happening on the FPGA? We have the live video coming in from the host’s CPU and that’s being decoded on the FPGA using H.264 Decoder, and scaled into multiple resolution using adaptive [inaudible] scaler. And these scaled resolution videos are again to be encoded with the better quality encoder, and sent out back to the host.
Uma Madhugiri Dayananda: Here is this video transcoding stack that Xilinx offers. I work end to end on this pipeline. Building FFmpeg applications, XMA plug-ins, testing these applications on different SDAccel boards, targeting different devices. And not just these, I also work on video algorithms, including the quality, for improving the quality, and benchmarking encoders from partners according to customer requirements, so… I guess that makes me a Girl Geek. I work on things that I’m passionate about, video compression technologies.
Uma Madhugiri Dayananda: What I would like you to take away from this talk is FPGAs give you better performance, better adaptable and reusable, and you don’t necessarily have to be a hardware engineer to use FPGA, you can be a software engineer and still use FPGA to isolate your application. Thank you.
Eva Condron-Wells: Thank you so much, Uma, and to all of our lightening talk presenters. Let’s shift gears to our panel of senior Xilinx leaders. Here to lead our panel discussion is Tom Wurtz, Senior Director of Documentation and Program Management. And our distinguished panel.
Tom Wurtz: So tonight we’re going to explore the topic of acceleration. We’ve got a great panel of senior Xilinx leaders here to enjoy the [inaudible] discussion. So we’re going to start with Jayashree Rangarajan. She’s a Senior Director of Software Development. And her Girl Geek power is simplifying solutions to complex engineering ideas. We’ve also got Lori Pouqeutte, who’s our Vice President of Global Customer Operations, and her Girl Geek power is knowing what the customer wants and needs before they know what they want and need. All right. Next up is Jennifer Wong, and she is a Vice President of FPGA Product Development, and her Girl Geek power is optimizing results for both engineering and management. And finally, we have Ambs Kesavan, who’s our Senior Director of Software Infrastructure, Engineering & DevOps, and her Girl Geek power is improving the development efficiency of using tools both in the cloud and on something.
Tom Wurtz: All right, so let’s talk about this acceleration, that’s a pretty wide topic. We’re going to take it in a couple of different directions. First, computational acceleration. And then we’re going to make it a little bit more personal and talk about careers, as well as teamwork. So, we’re going to start with the hard stuff. So we’re going to geek out a little bit on computational acceleration. You heard Changyi talk earlier about machine learning. So this is things like image classification, motion detect, and speech recognition. So Ambs, I’m going to have you go first, and I’m going to have you talk us through some of the bottlenecks and challenges in this.

Senior Director of Software Infrastructure Engineering and DevOps speaking at Xilinx Girl Geek Dinner.
Ambs Kesavan: Thanks, Tom. I actually view this as an opportunity rather than a challenge. So, I’ll talk about the opportunities here and I’ll explain why I view that way. So we are in an era of big data, and there is a lot of statistics about big data. And I was looking at a recent article that said every single second, we generate about terabytes of data from connected devices and sensors around us, and 70% of this data is video. And that amounts to about 800 million hours every single day or something like that, and businesses are trying to take advantage of this data. They want to mine the data, to be able to look through things. One is for better customer service and also in [inaudible].
Ambs Kesavan: So machine learning applications are getting innovated at that rapid pace, in every single industrial segment, whether it is retail, or finance, or healthcare, Uma talked about video transcoding, speech recognition, name it. Every single industry is going through innovation. And these machine learning applications, they actually have the most algorithms for actually doing the machine learning. And these algorithms, if you run on CPU, that is no longer sufficient. It is not a scalable given the massive volume of data that we are looking at.
Ambs Kesavan: So acceleration is the way to go. And innovation needs to happen both in hardware, also in software, in order to accelerate this machine learning applications and algorithms. And that’s the opportunity, Tom. And Xilinx is well positioned Tom, [inaudible].
Tom Wurtz: Thanks. Lori, maybe you can join in with a few more thoughts.

VP of Global Customer Operations Lori Pouquette talks about opportunities and challenges in supply chain for applying machine learning to the business at Xilinx Girl Geek Dinner.
Lori Pouquette: Sure, and I’ll take this more from the practical application in business. So we’re building a lot of capabilities to accelerate machine learning, but we actually have to apply that too in our business. And in supply chain… There’s quite a bit of opportunity in supply chain for applying machine learning to the business. And it provides good ROI to the business. A couple of the areas that we’re looking at are, what I call predictability or or predictable analytics. And one of the applications would be being able to understand the profile of the die that is coming out of the fab very early on, so you can actually match that to the demand much earlier in the work stream and optimize the use of your materials. Another predictable application is actually in the back end, when you talk about equipment. One of the things that shuts us down is unplanned machine downtime. So if we can anticipate and understand the profiles of the machinery so that we prevent it from going down in the first place, it’ll definitely propel the business. The challenges with all of this, though, are the massive amount of data that you have to gather to really train your models and make sure you have the right algorithms, so you get the ROI out of it.
Tom Wurtz: So there’s clearly a lot of opportunity is this space, so… You see companies like Google and Intel, they’re doing these dedicated AI chips, there’s dozens of startups that are actually going down this path as well. And maybe Jayashree, you can walk us through kind of what you see in terms of where is the market going from here.
Jayashree Ranga: You all heard Ambs talk about the terabytes of data getting generated. And there’s also… She was mentioning about algorithms that need to be developed… And specifically, if you look at the computing today, CPUs generally are meant for general purpose computing. When you talk of AI, and machine learning in particular, you have two types of learning. There is training, and then there is inference, right. And then training, you use all of this data that you have accumulated and we are training certain models to do a particular task, [inaudible] domain, or [inaudible] exploration, or whatever. But then, when you have to deploy that model, actually for doing the inferencing, you want this to be done in such as way that the computation happens a lot faster and the CPUs are not scaling… You probably have heard at many conferences that [inaudible] are not scaling anymore.
Jayashree Ranga: So there is a need for us to be looking at how can we accelerate the solutions that are targeted for these specific applications. So, now you’re seeing companies looking for like… Especially the examples that, Tom you gave about the GPUs and the… That’s primarily because they saw a need for how do I accelerate this? I can’t do it just with software, I need to be building custom hardware. And, it doesn’t just stop the building that accelerator, but you’ll need to have some surrounding support in the system because data that needs to come into that accelerator, and how’s the communication going to happen? So there is a need for these specialized architectures to be built and that’s why are seeing a lot of these startups getting funded to find that next big accelerator architecture that we can build.
Jayashree Ranga: Second thing with machine learning also is you probably are hearing new networks getting created everyday, right. Which means you want an architecture that you don’t build for one network, but two years later you’re not able to use it. So, you want to a hardware architecture that is scalable with the needs. And that’s an area where Xilinx’s provided solution, which is adaptable and reusable, you saw it in the presentations earlier, it provides solutions that people can use for building networks that gets scaled with new models that come in. Especially with the startups that you’re talking about, I’m waiting to see as well, which ones succeed, which ones get taken over.
Tom Wurtz: Yeah. So adaptability, programmability, is part of the Xilinx DNA. So, when we think about programmability, there’s the idea of buying a chip off the shelf and programming it to do what you want. But there’s also the notion of, once that chip is actually in operation, being able to turn off part of it, and reprogram just that part to take on a different workload. And it’s part of the general philosophy of Xilinx, and as we look forward to the next generation of chips, it becomes even more impressive what we’re planning to do, so… Jennifer, maybe you can walk us through what Versal looks like.
Jennifer Wong: Earlier I see a lot of hands go up when we ask “Who knows about Xilinx?” So I saw a lot of hands go up. Then I heard, “How many people are hardware engineers here?” So I do see quite a few hands go up. So I wouldn’t be surprised that some of you here are some of our customers, or you have used our products, it depends… When you were in school… So you must be very familiar with our earlier product lines like UltraScale or UltraScale Plus.
Jennifer Wong: So Versal, it’s a significant step up of UltraScale, UltraScale Plus in terms of performance. So what is Versal? Versal is our first 7 nanometer product, TSMC’s latest process node, and is the industry’s first ACAP. ACAP stands for adaptive compute acceleration platform. But this is truly a platform device, not your old FPGAs. Though I should say this is the really revolutionary architecture. So this revolutionary architecture combines a scalar engine, an adaptive engine, an intelligent engine, to give us this significant performance improvement. The performance improvement can go up to about 20x of today’s GPU, or 100x up to today’s CPUs.
Jennifer Wong: So, now , how do we achieve this kind of a performance improvement. It’s pretty impressive. So, given today’s focus topic is machine learning and compute acceleration, I’m going to talk a little bit about the intelligent engine. Intelligent engine is also known as AI engine. Internally, we have a name called AI engine. So this is specially designed for compute intensive applications, like machine learning and wireless operations. Now go to the next level, what is AI engine made up of? It is really a wide array of integrated DSP engines, which are capable of [inaudible] and complex MAC operations. Now we have all these very very powerful engines. We need to think about how to connect them together in order to take advantage of them in terms of hardware acceleration.
Jennifer Wong: So you have used our products before, you must know MPSoCs. So, in MPSoCs we have a processor subsystem sitting alongside with the FPGA fabric. And these two entities are sitting side by side with some interface in between them, but the bandwidth is relatively limited. So, when they operate, they are operating fairly independently. So the difference between the older generation products and Versal is we added a very powerful NoC engine in between all these powerful engines. NoC stands for network on chip. This is not new in the industry, so NoC is very standard in ASIC. But what we are doing here is applying it to our architecture in order for us to leverage their compute acceleration.
Jennifer Wong: So what is compute acceleration, or hardware acceleration? It is… What it is a design when you can partition the area that are very very performance critical. So you partition it out, and put it into these powerful engines, and use compute acceleration to make the performance improve. And then, after the partition, you can have the slower function continue to run on the processor’s subsystem. And that’s how you achieve the big performance gain. And I’m going to stop right here, there are other innovations in Versal architecture. I’ll be happy to talk to you, if you’re interested, later this evening.
Tom Wurtz: Thanks, Jennifer. Versal is definitely an example of technology escalating at an incredible pace. So I’m going to ask each of you to kind of give some thoughts on where you think the things are going to go in the next three to five years in the acceleration space.
Jennifer Wong: Maybe I’ll just follow up on what I just said. So today’s product, what we have today is pretty big. If you look at our die size, it’s huge, and power is pretty high. So, they’re going to data center, into the cloud. And I see this intensive computation not stopping, because this is in the very early stage and I see that continue to go. But in three or five years, as our process becomes more mature, our technology become more advanced, I see more and more functions going to the edge devices, like mobile phones in your hands today. And I think in future, that’s where it will go.
Ambs Kesavan: So, Jennifer let me add a slightly different viewpoint. We talk quite a bit about computer acceleration. Even tn the presentations we heard about computer acceleration, and here what happens is you’re transferring massive amounts of data from storage to compute, doing that acceleration. And then transferring the results back to storage, and there is lot of data movement happening back and forth. And that’s not necessarily very efficient, you’ll run into [inaudible] storage, and networking. And every single data center, whether it is cloud data center or on ground data center, you’re going to have compute, storage, and networking. So, what if you do the computation closer to storage? So you’re actually doing the acceleration closer to storage instead of doing the data transfer back and forth. And that’s the area Xilinx is innovating and that’s… One example that I can give is the smart SSD announcement, that happened couple of months ago, when Samsung had it’s tech day. And that precisely is doing acceleration at the storage itself. And there is also similar innovation happening on the networking with SmartLynq. So it essentially, it’s converge solution with computer acceleration, storage acceleration, and networking acceleration, and that’s where the industry, I think, will benefit a lot.
Tom Wurtz: Maybe you could talk about the software a little bit, Jayashree.

Senior Director of Software Development Jayashree Rangarajan speaks on a panel discussion at Xilinx Girl Geek Dinner.
Jayashree Ranga: So, if you look at where a lot of this machine learning development is happening, it’s happening on the cloud. And they are the software developers. Throughout [inaudible] Niyati’s presentation, data scientists are looking at these massive amounts of data and looking at how am I going to write the right algorithm to solve this problem, right, and they are operating at higher levels. So what I see happening with the software is many layers of libraries being built, where these are libraries probably optimized to work for the hardware architecture that we’re targeting. Not necessarily done by the data scientists, but it’s provided by the company that is also delivering the hardware. Plus, there’s probably going to be AI specific library. For instance, we talked about video transcoding. So if you have open CV libraries that need to be provided for you. If your are software operator, you will understand this, right. Because we don’t… Anymore write string compares and stuff. You use [inaudible] libraries or SDL. So you are going to see stacks of libraries built, which are the highest level the application developer… Whether they are in a Caffe framework or a FFmpeg framework if they’re dong video transcoding. They’re going to leverage these libraries.
Jayashree Ranga: So I see a lot of innovations happening in that realm. And companies will be providing their own libraries. I see open source development or certain APIs that can be leveraged by people who are trying to address a lot of machine learning problems and various [inaudible].
Lori Pouquette: And then, if you take that from the engineering world to “Where is this all going to be used?” Xilinx has long been serving multiple end market segments, from automotive, to communications, tested measurement, medical, but our new focus now is on the data center area. The proliferation of the data, the video, it’s all going to be needing to be stored up in the cloud or on the premises. So we’ve really now got this strong focus on data center. And as part of that, in addition to selling our semiconductor devices, we’ve also started to sell boards. So we have Alveo product, which you heard Eva talk about earlier, you can see it in the demo room. So this is now making the acceleration capability, from just the semiconductor to enabling the customer with a board. So they can use the board and then go on to their design work for their entire solution much faster. They don’t even have to just start with the FPGA.
Lori Pouquette: Now, as we go out into time, what’s going to be really good for everybody is, we’re still serving all these other in markets, and as in markets like automotive really get into advanced autonomous drive or advanced applications, they’re all going to need to store that information somewhere. And they’re all going to need to process that information, and they may need to do that at the edge very rapidly, or they may be able to do that in a central place. But, basically what we’re doing here with acceleration isn’t just going to serve the base acceleration market, but all of our markets.
Tom Wurtz: Well we got pretty hard there to the extent that we pretty much used up most of our time. But I do want to take one moment to ask each of your, if you were to put into one single word, what does it take to actually accelerate a team, what would that be? And let’s start with you, Ambs.
Ambs Kesavan: Communication.
Jennifer Wong: Teamwork for me.
Lori Pouquette: Focus.
Jayashree Ranga: I’m going to go with two words, I would say it’s the winning attitude.
Tom Wurtz: All right. Thank you very much for all of our panelists.
Eva Condron-Wells: Thank you so much to our panelists and to our lightening talk presenters. At this time we’d like to open it up to the floor. And I’ll need to steal a microphone from one of our panelists, so we’ll share. Pardon me. Thank you.
Eva Condron-Wells: So, you’ve heard a lot of different insights, different perspectives. We’d like to hear a few questions. We probably have time for… We’ll take three. So… And we’ll continue the conversation afterwards. So if you’re still burning… You have a burning question in your mind, please know that we are planning to be here until 9:00, and we have plenty of demos to share too. So… And don’t forget to take your gift on your way out, I want to say that before you mentally leave… While I have your attention, that we have a gift for all of you, that we would like you to take on your way out, in the lobby of when you came in. So, please be sure to take that with you.
Eva Condron-Wells: So, that said, I’ve given you a little bit of time to think about your question, and I have a microphone right here. Come on up, let’s have… If you don’t mind saying your name and your question to our panel.
Sara Biyabani: Sara Biyabani, GridComm CTO. So the question I have, for engineering… We talked about acceleration, so I want to start with FPGA is a [inaudible] processors, you know, they’re part of the screen, right? They’re not the… Well, I mean they could be the star, they could be the diva. So then there’s the processor, right, and you’re not going in the space, competing with x86 or R. So what does that architecture look like? What’s your ideal architecture?
Jennifer Wong: I think we have a pretty good… We do have a processor. So we have a… So for the Versal we have the A72 cores, we a have a dual A72 core in the processor subsystem, in the scalar engine, what we call the scalar engine these two processors, subsystem, you a two A72 cores and then two R5 cores in there. So from a processing standpoint, we do have capability of doing that. And now we added a lot of these architecture that we can accelerate functions. So that is what we think were our niches. So we can partition it where very critical functions, we can put it into the more expensive side. We use a lot of silicon area for acceleration hardware. So we would smartly do that, and say, okay, “What is the important one that we can partition out, put it into hardware acceleration, and leave the processor still running?” So that is what we think where the niche. Everything is on one piece of silicon. So think about it, if you’re doing it outside, you have processors and other components. So, the interface takes a very long time. The key is integration for us. Everywhere, the smaller the footprint, the more integration you do, the more performance you… Both performance and power. So, whenever you got our chip, power is a big deal. So, performance and power both are advantage to integration. And that’s where we think we going in future.
Eva Condron-Wells: Thank you, Jennifer. We have actually three questions just popped up, right all in the same area. So we’re going with that energy, and please, your name and your question.
Sylvita: Hi, I’m Sylvita. First of all, thank you to Xilinx for hosting this event. Given all the other Girl Geek Dinners I’ve been, it’s nice to see somebody on the hardware chip design side kind of take a lead here. So my question is related to that. Because most of the discussion in the big data, enterprise SaaS, or AI has been around the software and the algorithms. The first time I saw a focus on hardware was actually a Startup Grind where one of the presenters talked about , don’t write off the chip guys here, because there’s a next revolution coming where we’re going to see a lot of custom built chips for AI applications. And given that we’re talking about… First of all, this is a Girl Geek Dinner, and given that we’re talking about the fact that we need women to be on an equal footing in the way that the AI is going to evolve, what are some of the ideas you might have for some of the younger folks to continue in this space?
Jayashree Ranga: Mic check? Can you hear me okay?
Jayashree Ranga: I can think of a couple of things, right. Computer architecture, ’cause as I was talking earlier about, hey there’s many architectures that need to… They’re probably waiting to be innovated, right, because we are talking of machine learning in many many domains and stuff. So I do think, as young women who are looking to hey, what do I want to do if I want to enter into hardware, I think having a good grounding in computer architecture principles is going to go a long way. And just learning the hardware aspect, alone, is not going to be sufficient. You also need to understand which domain you’re targeting. So you need to know the end customer that you’re going to be influencing. So you need to learn about the software component, also. So I think, if you want to excel in both sides, as you are getting your early education, having good grounding in both hardware principles as well as software programming principles help you better understand the needs on both sides. But as you go further, and you are looking to specialize, then at that point, it’s an individual style choice as to whether hardware attracts you more or software attracts you more. But I think it’s good to keep your options open.
Eva Condron-Wells: Great. Thank you so much. We’ll take two more questions, and then continue with our networking.
Mung: Okay, and my name is Mung. I’m a software engineer working hardware design company. You already addressed a little bit about that, and I just wonder if you can address a little bit more regarding into FPGA application in machine learning and hardware acceleration to win over ASIC in that field.

VP of FPGA Product Development Jennifer Wong speaking at Xilinx Girl Geek Dinner.
Jennifer Wong: I think the jury is still out, but I think everybody is working very hard. This is a very hard space. And I think everybody is trying a very different route. And Xilinx has Xilinx’s niche. And I think what we give here… What our specialty is, is we are reconfigurable. Aside from being able to partition… That’s definitely a big deal, we can allow software to run on software, hardware fabric to run on past hardware… The bigger part, I think, is the reconfiguring part, which I didn’t talk about earlier. So we talked about many many different workloads today. During the day, the data center can be running one kind of work load, in the evening it’s a different workload. So, what we excel, here, is we allow reconfiguration. So even you can… Within the ACAP, you can run different workloads at different times, with the exact same piece of hardware. So we believe that is a very big niche that we can further leverage in this particular space.
Eva Condron-Wells: Thank you.
Lori Pouquette: I just want to add that, beside the reconfigurability, there’s the costs. So the costs of doing ASIC is becoming prohibitive for many applications. So on higher volume applications it’s still an option. But many of our customers who might’ve classically done ASICS, are moving away from it because it’s just not making financial sense. So there’s that piece of it too.
Eva Condron-Wells: Thank you, Lori. And our final question.
Wolfgang: Hello, my name is Wolfgang. I’m a hardware engineer. And I want to thank you that I have the chance to ask a question even though I am not a Girl Geek. So, my question is about reliability. When we have Ultra high speed computations in applications such as control of industrial processes or autonomous driving, it is not only imperative that those computations are very fast, but the results need to be very reliable. And we don’t always have the option to just [inaudible] processing memory because we have a sensor somewhere, a camera, it sends data to some processor, and that processor has to make a decision and send it to some machine that needs to act and do the right thing. So what are your thoughts about reliability, or maybe a hint, it has to do with something with high speed interfaces and a robustness against big errors, but there are also many other aspects to that.
Eva Condron-Wells: Thank you.
Jennifer Wong: Okay, so reliability has always been a big issue for us. In the past, what we do is we allow [inaudible] reliability and we do things very carefully with our foundry. Because foundry give us some specs that we have to follow through. TSMC is pretty well known in terms of it being rather conservative. So, they give us specs and we obviously negotiate with them. There is a little but of push you can do, because everybody is competing for performance and power. The more you can push the foundry, the more you can gain the advantage. So, this is maybe against what you are asking, but what I’m trying to say here is we do a very [inaudible] balancing act in terms of balance versus reliability. We don’t completely ignore reliability. We go for performance, but we always make sure we can meet our reliability. And we do a very very thorough quality QA in the end. And, also, we have qualification… Pretty substantial qualification… Different time, maybe you can add to it.
Lori Pouquette: Yes. So on the quality side, we have many in markets we serve. So we have commercial grade, we have automotive grade, and we even have an aerospace… So all of those have different levels of quality and reliability qualifications that we go through. So we definitely are very attuned to the upcoming challenges of the technology to be able to respond quickly in those types of situations you’re describing. But we definitely offer a variety, and do quite a bit of different qualifications depending on the markets that we’re serving.
Eva Condron-Wells: All right. Thank you all so much for your very thoughtful questions. And thank you all, our guests, our speakers, panelists, for your insights. We genuinely appreciate you taking the time to share your insights with this team and group. So, that said, we are officially closing our technical talk. But we are not done with our evening yet, and we are happy to stick around and answer more questions. Some of our Xilinx employees are wearing “ask me about” stickers, you’re welcome to engage with them. I will be wearing one too, so find me later. And of course, we have our dessert, and networking, and demos. Thank you all so much. This concludes the technical talk, thank you.

Applause from the girl geeks at Xilinx Girl Geek Dinner after the panel discussion. Thanks for joining us in San Jose!
Our mission-aligned Girl Geek X partners are hiring!
- See open jobs at Xilinx and check out open jobs at our trusted partner companies.
- Find more Xilinx Girl Geek Dinner photos from the event – please tag yourselves!
- Does your company want to sponsor a Girl Geek Dinner in 2021? Talk to us!
