VIDEO
The terms AI (Artificial Intelligence) and ML (Machine Learning) are the new software industry buzz words that promise to take your security and operations practice to the next level, but…do they? In this session, Melisa Napoles hits on what works and what doesn’t work when organizations embark on their ML journey. She’ll cover her favorite lessons learned from organizations who are successfully on their way to finding real anomalies within their practice and with more data and precision than ever before! Do you ever wonder if you’re behind, ahead or right at the helm of what all your peers are doing with ML? Come find out!
Transcript of Elevate 2020 Session
Sukrutha Bhadouria: All right. Up next, Melisa Napoles, we’re so excited to have, will be our next speaker. She’s a solutions engineer at Splunk, where she helps customers solve interesting data problems in security operations, as well as in business intelligence. Melisa will now be sharing with us her favorite lessons learned from organizations that jumpstart their machine learning journeys in cyber security. Welcome, Melisa, and thank you so much for making time for us.
Melisa Napoles: Excellent. All right, I’m going to go ahead and share my screen. All right. Can you confirm you guys see my screen all right?
Sukrutha Bhadouria: Yes, we can see your screen.
Melisa Napoles: Excellent. Well, hi everyone. Thank you for those of you who are still on with us, and hello to those of you who are just now tuning in. For the next 15 minutes or so, we’re going to hopefully get you all out of here having jump-started or substantiating your knowledge around doing machine learning and cyber security.
Melisa Napoles: All right. Here’s what I have for our agenda the next 15 minutes. When I think about jump-starting this journey and I think about all the clients I’ve worked with, it feels natural to me to segment the conversation in these four areas. Before jumping right into it, though, I’m going to take just a moment to tell you a little bit about me so you can put some history with the face on the other side of the screen here with you.
Melisa Napoles: I moved around a lot growing up, and this slide just talks about what makes me me. As my company likes to call it, these are my million data points. My family immigrated to the United States from Cuba, so I am first generation born American. After graduating from school and having various internships and consulting experience, technical specialist experience, sales engineering experience, I landed myself at a big data company called Splunk. I currently live out of Chicago, Illinois, supporting some of our larger Splunk customers, but my heart is somewhere between Miami, Florida and Seattle Washington, where I have my family. They say that your home is where the heart is, right? That’s a bit about my situation.
Melisa Napoles: And what being a solutions engineer really means is that I’m sort of like a consultant with Splunk solutions and everything Splunk touches, which is a lot of things. Splunk got its initial start in IT and security, but it’s since translated into a platform that serves almost every business unit in an organization. And the reason that’s cool is it’s allowed me to be exposed to how businesses run their practices, in particular, their cyber security practices. And so from this work over the last five years now, there are certainly patterns that have emerged to show what really good looks like in a cyber security practice, embarking on machine learning and what not so good looks like and some of the things that cause organizations to stalemate and not be able to move forward. In this particular visual, something that I’m particularly proud of in working here at Splunk is we just have absolutely stellar, quality female engineers, and I’m thankful to have that support system around me.
Melisa Napoles: All right, so let’s jump right into it. When I first started working in this space, it took me a good long while to really get the gist of AI and ML, and I went to school for physics and I took a lot of math classes. I was pretty much forced to figure it out because of the clients I was working with and the questions they were asking me that ultimately I was also asking. And what I learned is that for starters, ML, or machine learning, is a subset of AI or artificial intelligence, to put it simply. AI is the broader concept of machines being able to carry out tasks in a way that we would consider smart, and ML is an application of AI based around giving machines access to data to make some decisions on their own. It’s really not as scary as people make it seem. And when we’re talking about cyber security in particular, I’m finding that many organizations are really still in the realm of the machine learning area, at least today.
Melisa Napoles: When I embarked on this journey a few years ago, I also ran into asking, “Well, is machine learning statistics or is it not?” And even to this day, I get organizations asking me this, trying to understand this on their own, too. And what I’ve learned is that machine learning is very much based off statistics. And the main difference between them is their purpose. All ML certainly uses statistics, but not all statistics can necessarily be classified as machine learning. Statistic models are designed to make inferences about the relationships between data variables themselves and the machine learning models are designed to make the most accurate prediction off those inferences. It seems like everyone has an opinion about this these days, but this is the best conclusion I’ve come to, at least to date. We’ll see how long it lasts for, but this seems to be working in separating my logic in this space.
Melisa Napoles: And of course, like all good things, there are also lots of opinions on this sort of thing that you see quoted here as well. There’s comedy as a part of this quote, but I do find this to be true. At a very practical level, what ML typically represents when an organization is first starting out is in fact basic statistics. And right, this is just the thing that we all learn about in the mandatory high school or college stats class that we were forced to take.
Melisa Napoles: And so with all the buzz around machine learning and AI in the industry, you’d think everyone is doing it. Right? But what’s surprising is that organizations are not. And for those who are doing it, they’re running into major issues that effectively put a brick wall in front of them. And it’s really hard to get over. Oftentimes, I work on projects where a good number of organizations do, in fact, feel like this is all hype because they don’t know where to start or they got started too quickly and didn’t understand some of the foundational pieces to having longevity in this space, but it’s definitely not all hype.
Melisa Napoles: And so the way that I think about working with any data is like this. Everything we ever do with data for the most part can route back to a question we are trying to answer, a question that is formulated by our brains that we are trying to answer. And oftentimes those questions, if not all the time, can be categorized as your known knowns, the questions you know you need to be asking and in which you have confidence in how to find the answers, your known unknowns, the questions, again, you know you need to be asking, but you really are not very confident how to go about finding those answers and your unknown unknowns, the questions you don’t even know to be asking and you definitely don’t know the answers. Most organizations implementing machine learning and cyber security live in the first two spaces here, your known knowns and your known unknowns. Only the ones with extremely good resourcing can also say they’re incorporating the unknown unknowns, and we’ll talk about why that is.
Melisa Napoles: All right, so I’m going to give you just a moment here to see if you can count the number of bears on this visual. If any of you have played Where’s Waldo before, this as much the same. ML can help you reduce noise and look for the things you care about, the known unknowns, “I know I need to be asking about this, but I’m not really sure what the answer is or how to come about it.” Because we’re short on time, I’m going to jump to the next screen, and there they are. There are four bears, but that was a lot of noise to sort through, right?
Melisa Napoles: And keep in mind that I told you, you were looking for bears. What if you didn’t know to look for bears? What if you didn’t know they were representative of something you cared about? Because you knew to look for the bears, this was a known known. You knew the bears were what you cared about, so now where are they? Let me count them. Had you not known you were looking for bears, this would have been a known unknown, “I don’t know what’s anomalous here, but I know something likely is. Let me look for similarities and dissimilarities to find it.” You may ask why we used bears here and not just a Where’s Waldo visual. Fancy Bear is a Russian cyber espionage group. They target government, military, and security organizations, so think NATO and the like, and they try to steal secrets, hence finding your Fancy Bears.
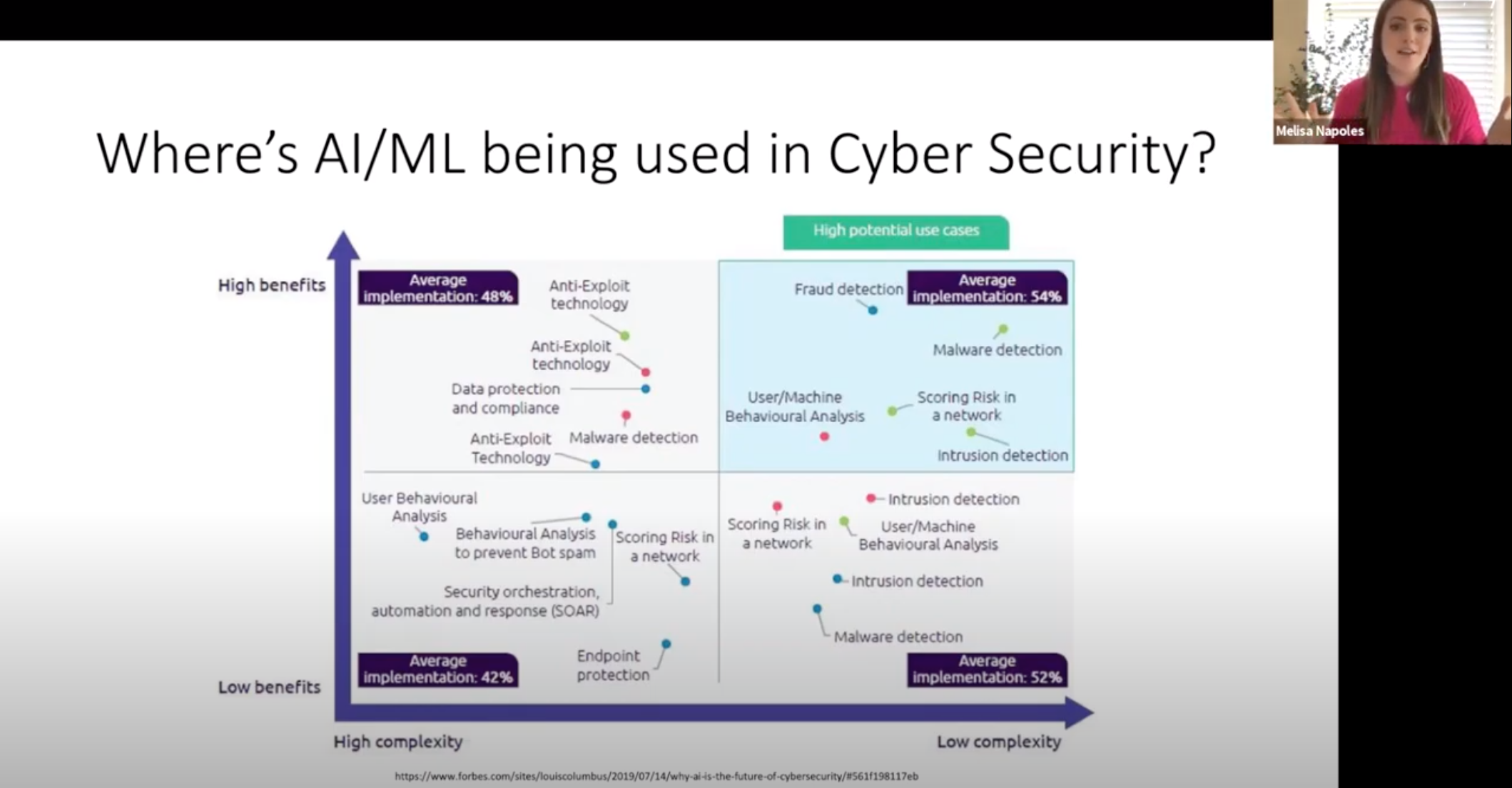
Melisa Napoles: And it’s easy to get overwhelmed with where to start with ML and cyber security or really ML in any practice, and you don’t have to be doing the most advanced things with ML to be getting incredible value. Go after, and what I often advise organizations, and the most successful ones, what I see them doing is going after what the industry likes to call low-hanging fruit. Go after the low complexity, high benefit use cases. What’s in the upper right hand quadrant here is representative of where I see organizations first implementing machine learning and where they’re very successful. When you see things like malware detection or intrusion detection, think about asking questions like, “Do I have employees visiting weird websites that have long complex URLs that are sort of unrecognizable and are not indicative of something normal? And if they are, how often do they do it? Are they doing it more than they normally do? And how do I even define what normal is? Is it no times and they’ve been there the first time? Is it more than five times?” Understanding what that normal is, is where machine learning is incorporating.
Melisa Napoles: When you see things like … We’ve got here, a variety of things, but even think about asking, “Do I have employees failing to log into their corporate-issued laptop more times than they normally do in a given period?” I’ll take myself in particular. I mean, I fail authentication on my laptop at least five times every single day for a solid week every time Splunk forces me to change my password. It’s just a habit. And with Splunk incorporating machine learning into cyber security practice, they should be able to ask, “Well, when is Melisa failing to authenticate on her laptop way more than she normally does?” So these are some things to think about.
Melisa Napoles: What’s working for organizations and where are they in their AI and ML journey besides what we’ve just talked about in that upper right hand quadrant? Most organizations get started on machine learning or anomaly detection in cyber security with static thresholds. Imagine for a moment that you’re part of a security organization and all that really means is your job is to protect the company from the bad guys and gals doing any variety of things. And you’re tasked with being able to answer, “When do I have employees failing to authenticate more times than they normally do, failing to log in more times than they normally do?” And the first way that organizations tend to answer this question is by saying, “Okay, well, let’s just set some static threshold in place.” In this case, in the visual I’ve got, it’s 100, so any data point where the failed logins are more than 100, I’m going to be notified. But how do I even know if 100 is the right number and if it’s the right number for every individual in my organization?
Melisa Napoles: Oftentimes, while that is an awesome way to start doing machine learning and cyber security in that particular one example, organizations will then often upgrade to incorporating statistics with standard deviation, so then being able to ask, “All right, well, instead of tell me when I’ve got employees failing to authenticate more than 100 times, tell me when I have employees failing to log in more than they normally would.” And so that’s what you see here.
Melisa Napoles: And so organizations will get here. They’ll live here for a while, but as they start to incorporate a larger volume of data, a larger variety of data, as they try to model this at the speed at which their data moves so that their models are not stale, they realize the three Vs, and the three Vs being volume, variety, and velocity, volume being more data means more history means more time to get to look back in those models, which is important for accounting for fluctuations in seasonality. What about your employee like me who fails to authenticate every six months when password refresh has happened? More variety of data, the more accurate your insights. And again, if your machine learning can move at the speed at which your data moves, you won’t have stale models, and that means you’ll be making more accurate decisions based on your insights.
Melisa Napoles: What happens typically next when organizations realize the three Vs is they then begin to incorporate fit and apply concepts or train and test concepts, essentially breaking up a single workflow with statistics into two workflows for scale so that we can account for the three Vs. Imagine for a moment that you have a data set that represents a fruit basket. You’ve got records for oranges and bananas and apples and grapefruits and you’ve trained that data set to recognize that when there’s a banana, the banana’s yellow and it’s curved so that when new data gets corroborated against that training data set and it sees a data point that is yellow and curved, it can say, “Oh, I know what that is. That’s a banana.” So that’s what incorporating train and testing concepts means. It’s really, in large, part starting to do what we call supervised machine learning.
Melisa Napoles: And sometimes at this point, organizations they’ll start to dabble in creating supervised machine learning models, but it gets to a point where you’ve got such a large volume and variety of data moving so quickly that it’s hard to know all the models you should be using to fit your data … because you don’t want to fit your data to a model, you want to fit the models to your data … that they bring in supervised and unsupervised solutions to help in the world of machine learning.
Melisa Napoles: And so the fit and apply concepts, I would say, fit more in the world of the supervised machine learning, but then you have those unsupervised machine learning models. And if you think about us talking about your unknown unknowns, that third aspect of your known knowns, your known unknowns, and then your unknown unknowns, the questions that you don’t even know to be asking, that typically falls under what unsupervised machine learning helps you solve.
Melisa Napoles: Here’s an example, just one example, one view, one solution of what unsupervised machine learning in the world of cyber security can look like. Forget all the antics of what’s on the visual here. What you’ll notice is if you follow my storyline, you’ve got seven distinct anomalies using machine learning, telling you a larger story of an employee’s account being hijacked and used to steal data. You see anomalies of a ridiculous amount of data being taken from the computer of the employee. You see the employee’s login being logged in from Chicago, from China, from Russia, right? That defies the laws of physics. It’s impossible. You see all these weird things happening in conjunction together that strung together by a bit of supervised machine learning and a whole lot of unsupervised machine learning over a two month period tell you a larger story of what’s happening, things that you wouldn’t have even known to ask about because you didn’t even know what the patterns were to be looking for.
Melisa Napoles: What’s holding organizations back from doing more, from getting to this point of doing unsupervised machine learning and any variety of other things in the world of AI? I firmly believe in all the clients I’ve worked with, small and large, across different industries in cyber security and even in other spaces, but especially in cyber security, it’s the fact that there’s not an onus on being a citizen data scientist, whether it’s leadership not promoting that or individuals not having that fostered within them. And being a citizen data scientist is not being a data scientist, but as the person who works with your data, who creates the data, who is most knowledgeable of your data, there’s nobody better than those people to understand the business impact of that data. And so that’s what it means to be a citizen data scientist, understanding some of the fundamentals so that you can take that data, work with your data science counterparts and really propel the business forward in doing machine learning, doing AI so that you can ultimately impact an organization’s bottom line, whether that’s efficiency or revenue or what have you.
Melisa Napoles: The most prevalent are what you see on the screen here, so don’t be intimidated by AI and ML. It’s very powerful, but it’s nothing that can’t be wrangled. Embrace that idea of being a citizen data scientist. You do not have to be doing the most advanced things with ML to be getting incredible value and have impact. And remember those three Vs, volume, velocity, and variety as you embark on really testing and playing with ML type things.
Melisa Napoles: Remember these concepts of training and testing in the world of supervised and unsupervised machine learning, and then lastly, we didn’t have enough time for it, but remember that you should never be forcing your data to fit algorithms. Rather, you should be able to pick algorithms that fit the flow of your data so that you have accurate insights and you can make really quite powerful data-driven business decisions.
Melisa Napoles: I am going to play a very quick video here, which I find to be very inspiring and works its way into the world of figuring out ways to use machine learning to advance really the business and the world.
Speaker: One inventor is Benjamin Franklin.
Speaker: Leonardo da Vinci.
Speaker: Thomas.
Speaker: Edison.
Speaker: Alexander Bell Graham.
Speaker: No.
Speaker: That’s kind of a tough one.
Speaker: Um.
Speaker: In school, it was always a male inventor, I just realized.
Speaker: To know that there were women before me…
Speaker: It gives me motivation that I can invent something, make maybe a change in the world, and that would be really cool.
Melisa Napoles: All right, so that was a campaign that Microsoft put out for International Women’s Day in 2016. I fell in love with it when I first saw it and I still watch it every now and again just to remind me of a few things.
Melisa Napoles: Lastly here, I do just … Let me see. There we go. What I have to remind myself of, and what I hope that I leave all of you with, is in the world of figuring out how to work with machine learning and not be intimidated by it, but find productive uses for it, don’t be afraid to go out there and really respectfully challenge the status quo.
Melisa Napoles: All right. That’s all from my part. Thank you so much to the Girl Geek organization for letting me speak with you all here today and also letting me learn from the rest of the speakers. It’s been a great event so far.
Sukrutha Bhadouria: Hi. Thanks so much, Melisa. This was great. I want to make sure to thank you for making time for this on a busy weekday. We have some questions that we will take offline, so they’ll be answered offline. Thank you so much, Melisa.
Melisa Napoles: No problem. Take care.
