VIDEO
More than 100 girl geeks met at OpenAI HQ in San Francisco to to connect with OpenAI researchers and learn about their recent work in reinforcement learning, robotics, AI policy, and more!
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- See open jobs at OpenAI and check out open jobs at our trusted partner companies.
- Find more OpenAI Girl Geek Dinner photos – please tag yourselves!
- Does your company want to sponsor a Girl Geek Dinner in 2021? Talk to us!

Girl Geek X team: Gretchen DeKnikker and Sukrutha Bhadouria kick off the evening with a warm welcome to the sold-out crowd to OpenAI Girl Geek Dinner in San Francisco, California. Erica Kawamoto Hsu / Girl Geek X
Transcript of OpenAI Girl Geek Dinner – Lightning Talks & Panel:
Gretchen DeKnikker: All right, everybody, thank you so much for coming tonight. Welcome to OpenAI. I’m Gretchen with Girl Geek. How many people it’s your first Girl Geek? All right, okay. Lots of returning. Thank you for coming. We do these almost every week, probably like three out of four weeks a month. Up and down the peninsula, into the South Bay or everywhere. We also have a podcast that you could check out. Please check it out, find it, rate it, review it. Give us your most honest feedback because we’re really trying to make it as awesome as possible for you guys. All right.
Sukrutha Bhadouria: Hi, I’m Sukrutha. Welcome, like Gretchen said, Angie’s not here but there’s usually the three of us up here. Tonight, please tweet, share on social media, use the hashtag GirlGeekXOpenAI. I also, like Gretchen, want to echo that we love feedback, so any way you have anything that you want to share with us. Someone talked about our podcast episodes today. If there’s any specific topics you want to hear, either at a Girl Geek Dinner or on our podcast, do share that with us. Either you can find us tonight or you can email us. Our website is girlgeek.io and all our contact information’s on there. Thank you all. I don’t want to keep you all waiting because we have amazing speakers lined up from OpenAI, so.
Sukrutha Bhadouria: Oh, one more quick thing. We’re opening up sponsorship for 2020 so if your company has not sponsored a Girl Geek dinner before or has and wants to do another one, definitely now’s the time to sign up because we fill up pretty fast. We don’t want to do too many in one month. Like Gretchen said, we do one every week so definitely would love to see a more diverse set of companies–continue to see that like we did this year. Thank you, all. Oh, and over to Ashley.

Technical Director Ashley Pilipiszyn emcees OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Ashley Pilipiszyn: All right, thank you.
Sukrutha Bhadouria: Thanks.
Ashley Pilipiszyn: All right. Hi, everybody.
Audience: Hi.
Ashley Pilipiszyn: Oh, awesome. I love when people respond back. I’m Ashley and welcome to the first ever Girl Geek Dinner at OpenAI. We have a … Whoo! Yeah.
Ashley Pilipiszyn: We have a great evening planned for you and so excited to see so many new faces in the crowd but before we get started, quick poll. How many of you currently work in AI machine learning? Show of hands. All right, awesome. How many of you are interested in learning more about AI machine learning? Everybody’s hands should be up. All right. Awesome. We’re all on the right place.
Ashley Pilipiszyn: Before we kick things off, I’d like to give just a brief introduction to OpenAI and what we’re all about. OpenAI is an AI research lab of about 100 employees, many of whom you’re going to get to meet this evening. Definitely, come talk to me. Love meeting you. We’ve got many of other folks here, and our mission is to ensure that safe, artificial general intelligence benefits all of humanity.
Ashley Pilipiszyn: To that effect, last year we created the OpenAI Charter. The charter is our set of guiding principles as we enact this mission and serves as our own internal system of checks and balances to hold ourselves accountable. In terms of how we organize our research, we have three main buckets. We have AI capabilities, what AI systems can do. We have AI safety, so ensuring that these systems are aligned with human values. We have AI policy, so ensuring proper governance of these systems.
Ashley Pilipiszyn: We recognize that today’s current AI systems do not reflect all of humanity and we aim to address this issue by increasing the diversity of contributors to these systems. Our hope is that with tonight’s event, we’re taking a step in the right direction by connecting with all of you. With that, I would like to invite our first speaker to the stage, Brooke Chan. Please help me welcome Brooke.

Software Engineer Brooke Chan from the Dota team gives a talk on reinforment learning and machine learning at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Brooke Chan: Yeah. Hello. Is this what I’m using? Cool. I’m Brooke Chan. I was a software engineer on the Dota 2 team here at OpenAI for the past two years. Today, I’m going to talk a little bit about our project, as well as my own personal journey throughout the course of the project.
Brooke Chan: We’re going to actually start at the end. On April 13th, we hosted the OpenAI Five Finals where we beat the TI8 world champions OG at Dota 2 in back-to-back games on stage. TI stands for The International, which is a major tournament put on by Valve each year with a prize pool upwards of $30 million. You can think of it like the Super Bowl but for Dota.
Brooke Chan: There have been previous achievement/milestones of superhuman AI in both video games and games in general, such as chess and Go, but this was the first AI to beat the world champions at an eSports game. Additionally, as a slightly self-serving update, OG also won the world championship this year at TI9 just a few weeks ago.
Brooke Chan: Finals wasn’t actually our first unveiling. We started the project back in January of 2018 and by June of 2018, we started playing versus human teams. Leading up to finals, we played progressively stronger and stronger teams, both in public and in private. Then most recently, right before finals, we actually lost on stage to a professional team at TI8, which was the tournament that OG later went on to win.
Brooke Chan: Let’s go back to the basics for a minute and talk about what is reinforcement learning. Essentially, you can think of it as learning through trial and error. I personally like to compare it to dog training so that I can show off pictures of my dog. Let’s say that you want to teach a dog how to sit, you would say sit and just wait for the dog to sit, which is kind of a natural behavior because you’re holding a treat up over their head so they would sit their butt down and then you would give them that treat as a reward.
Brooke Chan: This is considered capturing the behavior. You’re making an association between your command, the action and the reward. It’s pretty straightforward for simple behaviors like sit but if you want to teach something more complicated, such as like rolling over, you would essentially be waiting forever because your dog isn’t just going to roll over because it doesn’t really understand that is something humans enjoy dogs doing.
Brooke Chan: In order to kind of teach them this, you instead reward progress in the trajectory of the goal behavior. For example, you reward them for laying down and then they kind of like lean over a little bit. You reward them for that. This is considered to be shaping rewards. You’re like teaching them to explore that direction in order to achieve ultimately your goal behavior.
Brooke Chan: Dota itself is a pretty complicated game. We can’t just reward it by purely on winning the game because that would be relatively slow so we applied this technique of shaped rewards in order to teach the AI to play the game. We rewarded it for things like gold and kills and objectives, et cetera. Going more into this, what is Dota?
Brooke Chan: Dota is a MOBA game which stands for multiplayer online battle arena. It’s a little bit of a mouthful. It’s a game that was developed by Valve and it has an average of 500,000 people playing at any given time. It’s made up of two teams of five and they play on opposite sides of the map and each player controls what’s considered a hero who has a unique set of abilities.
Brooke Chan: Everyone starts off equally weak at the beginning of the game, which means that they’re low levels and they don’t have a lot of gold and the goal is that over the course of a 30 to 60-minute game, they earn gold and become stronger and eventually, you destroy your opponent’s base. You earn gold and experience across the map through things like small fights or like picking people off, killing your enemy, taking objectives, things like that. Overall, there’s a lot of strategy to the game and a lot of different ways to approach it.
Brooke Chan: Why did we pick Dota? MOBAs in general are considered to be one of the more complex video games and out of that genre, Dota is considered the most complex. Starting off, the games tend to be pretty lengthy, especially in terms of how RL problems typically are, which means that strategy tends to be hard with a pretty delayed payoff. You might rotate into a particular lane in order to take an objective that you might not be able to take until a minute or a minute and a half later. It’s something that’s kind of like hard to associate your actions with the direct rewards that you end up getting from them.
Brooke Chan: Additionally, as opposed to games like Go and chess, Dota has partial information to it, which means that you only get vision around you and your allies. You don’t have a full state of the game. You don’t know where your enemies are and this leads to more realistic decision-making, similar to our world where you can’t like see behind walls. You can’t see beyond what your actual vision gives you.
Brooke Chan: Then, finally, it has both a large action and observation space. It’s not necessarily solvable just by considering all the possibilities. There’s about 1,000 actions that you can take at any given moment and the state you’re getting back has the value size of about 20,000. To put it in perspective, on average, your game of chess takes about 40 moves and Go takes about 150 moves and Dota is around 20,000 moves. That means that the entire duration of a game of chess really wouldn’t even get you out of the base in Dota.
Brooke Chan: This is a graph of our training process. On the left, you have workers that all play the game simultaneously. I know it’s not super readable but it’s not really important for this. Each game that they’re playing in the top left consists of two agents where an agent is considered like a snapshot of the training. The rollout workers are dedicated to these games and the eval workers who are on the bottom left are dedicated to testing games in between these different agents.
Brooke Chan: All the agents at the beginning of the training start off random. They’re basically picking their actions randomly, wandering around the map doing really awfully and not actually getting any reward. The machine in green is what’s called the optimizer so it parses in all of these rollout worker games and figures out how to update what we call the parameters which you can consider to be the core of its decision-making. It then passes these parameters back into the rollout workers and that’s how you create these continually improving agents.
Brooke Chan: What we do then is we take all of these agents and we play them against all the other agents in about 15,000 games in order to get a ranking. Each agent gets assigned a true skill, which is basically a score calculated on its win-loss records against all the other agents. Overall, in both training and evaluation, we’re really not exposing it to any kind of human play. The upside of this is that we’re not influencing the process. We know that they’re not just emulating humans and we’re not capping them out at a certain point or adding a ceiling on it based on the way that humans play.
Brooke Chan: The downside of that is that it’s incredibly slow. For the final bot that we had play against OG we calculated that it had about 45,000 years of training that went into it. Towards the end of training, it was consuming about approximately 250 years of experience per day. All of which we can really do because it’s in simulation and we can do it both asynchronously and sped up.
Brooke Chan: The first time they do get exposed to human play is during human evaluations. They don’t actually learn during any of these games because we are taking an agent, which is a snapshot and frozen in time and it’s not part of the training process. We started off playing against our internal team and our internal team was very much not impressive. I have us listed as 2K MMR, which is extremely generous. MMR means matchmaking rating which is a score that Valve assigns to the ranked play. It’s very similar to true skill. 2K is very low.
Brooke Chan: We were really quickly surpassed. We then moved on to contract teams who were around like 4K-6K MMR and they played each week and were able to give us feedback. Then in the rare opportunities, we got to play against professional teams and players. Overall, our team knew surprisingly little about Dota. I think there are about four people on our team who had ever played Dota before and that’s still true post-project, that no one really plays Dota.
Brooke Chan: This leads us to our very surprising discovery that complicated games are really complicated and we dug ourselves into this hole. We wanted a really complicated game and we definitely got one. Since the system was learning in a completely different way than humans, it became really hard to interpret what it was actually trying to do and not knowing what it was trying to do mean we didn’t know if it was doing well, if it was doing poorly, if it was doing the right thing. This really became a problem that we faced throughout the lifetime of our project.
Brooke Chan: Having learned this, there was no way to really ask it what it was thinking. We had metrics and we could surface like stats from our games but we were always leveraging our own intuition in order to interpret what decisions it was making. On the flip side, we also had human players that we could ask, but it turned out it was sometimes tough to get feedback from human players.
Brooke Chan: Dota itself is a really competitive game, which means that its players are very competitive. We got a lot of feedback immediately following games, which would be very biased or lean negatively. I can’t even count the number of times that a human team would lose maybe like, “Oh, this bot is terrible” and I was like, “Well, you lost. How is it terrible? What is bad about it?” This would create this back and forth that led to this ultimate question of is it bad or is it just different? Because, historically, humans have been the source on how to play this game. They make up the pro scene, they make up the high skill players. They are always the ones that you are going to learn from. The bots would make a move and the humans say it was different and not how the pros play and therefore, it’s bad. We always had to take the human interpretation with this kind of grain of salt.
Brooke Chan: I want to elaborate a little bit more about the differences because it goes just beyond the format of how they learn. This game in general is designed to help humans understand the game. It has like tooltips, ability descriptions, item descriptions, et cetera. As an example, here’s a frozen frame of a hero named Rana who’s the one with the bright green bar in the bottom left. She has an ability that makes you go invisible and humans understand what being invisible means. It means people can’t see you.
Brooke Chan: On the right, what we see is where we have like what the AI sees and it’s considered their observation space, it’s our input from the game. We as engineers and researchers know that this particular value is telling you whether or not you’re invisible. When we hit this ability, you can see that she gets like this little glow to her which indicates that she’s invisible and people understand that. The AI uses this ability and sees that the flag that we marked as invisible goes from 0 to 1 but they don’t see the label for that and they don’t really even understand what being invisible means.
Brooke Chan: To be honest, learning invisibility is not something trivial. If you’re walking down the street and all of a sudden, you were invisible, it’s a little bit hard to tell that anything actually changed. If you’ve ever seen Sixth Sense, maybe there’s some kind of concept there, but additionally, at the same time, all these other numbers around it are also changing due to the fact that there’s a lot of things happening on the map at once.
Brooke Chan: Associating that invisibility flag, changing directly to you, activating the ability is actually quite difficult. That’s something that’s easy for a human to do because you expect it to happen. Not to say that humans have it very easy, the AI has advantages too. The AI doesn’t have human emotions like greed or frustration and they’re always playing at their absolute 100% best. They’re also programmatically unselfish which is something that we did. We created this hyper parameter called team spirit which basically says that you share your rewards with your buddy. If you get 10 gold or your buddy gets 10 gold, it’s totally interchangeable. Theoretically, in a team game, that should be the same case for humans but inherently, it’s not. People at its core are going to play selfishly. They want to be the carrier. They want to be winning the game for the team.
Brooke Chan: All these things are going to influence pretty much every decision and every behavior. One pretty good example we have of this is called buybacks. Buybacks is a mechanic where when you die in the game, you can pay money in order to immediately come back to life and get back on the map. When we first enabled the AI to do this, there was a lot of criticism that we got. People were saying, “Oh, that’s really bad. They shouldn’t be wasting all their money” because the bots would always buy back pretty much immediately.
Brooke Chan: Over time, we continue doing this behavior and people kept saying, “Oh, that’s bad. You should fix it.” We’re like, “Well, that’s what they want to do.” Eventually, people started seeing it as an advantage to what we had, as an advantage to our play style because we were able to control the map. We were able to get back there very quickly and we were able to then force more fights and more objectives from it.
Brooke Chan: As a second self-serving anecdote, at TI9, there were way more buybacks way earlier and some people pointed this out and maybe drew conclusions that it was about us but I’m not actually personally going to make any statement. But it is one example of the potential to really push this game forward.
Brooke Chan: This is why it was difficult to have human players give direct feedback on what was broken or why because they had spent years perfecting the shared understanding of the game that is just like inherently different than what the bots thought. As one of the few people that played Dota and was familiar with the game and the scene, in the time leading up to finals, this became my full-time job. I learned to interpret the bot and how it was progressing and I kind of lived in this layer between the Dota community and ML.
Brooke Chan: It became my job to figure out what was most critical or missing or different about our playstyle and then how to convert that into changes that we could shape the behavior of our bot. Naturally, being in this layer, I also fell into designing and executing all of our events and communication of our research to the public and the Dota community.
Brooke Chan: In designing our messaging, I had the second unsurprising discovery that understanding our project was a critical piece to being excited about our results. We could easily say, “Hey, we taught this bot to learn Dota” and people would say, “So what? I learned to play Dota too. What’s the big deal?” Inherently, it’s like the project is hard to explain because in order to understand it and be as excited as we were, you had to get through both the RL layer which is complicated, and the Dota layer which is also complicated.
Brooke Chan: Through planning our events, I realized this was something we didn’t really have a lot of practice on. This was the first time that we had a lot of eyes on us belonging to people with not a lot of understanding of reinforcement learning and AI. They really just wanted to know more. A lot of our content was aimed at people that came in with the context and people that were already in the field.
Brooke Chan: This led me to take the opportunity to do a rotation for six months on the communications team actually working under Ashley. I wanted to be part of giving people resources to understand our projects. My responsibilities are now managing upcoming releases and translating our technical results to the public. For me, this is a pretty new and big step. I’ve been an engineer for about 10 years now and that was always what I loved doing and what I wanted to do. But experience on this team and growing into a role that didn’t really exist at the time allowed me to tackle other sorts of problems and because that’s what we are as engineers at the core, we want to be problem solvers.
Brooke Chan: That’s kind of my takeaway and it might seem fairly obvious but sometimes deviating from your path and taking risks let you discover new problems to work on. They do say that growth tends to be at the inverse of comfort so that means that the more you push yourself out of your comfort zone and what you’re used to, the more you give yourself opportunities for new challenges and discovering new skills. Thank you.

Research Scientist Lilian Weng on the Robotics team gives a talk on how her team uses reinforcement learning to learn dexterous in-hand manipulation policies at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Lilian Weng: Awesome. Cool. Today, I’m going to talk about some research projects with that at OpenAI robotics team. One big picture problem at our robotics team is to develop the algorithm to power general-purpose robots. If you think about how we humans are living this world, we can cook, we lift to move stuff, we add some more items with different tools. We fully utilize our body and especially our hands to do a variety of tasks. To some extent, we are general-purpose robots, okay?
Lilian Weng: That’s, we apply the same standard to our definition of such a thing. A general-purpose robot should be able to interact with a very complicated environment of the real world and able to manipulate all kinds of objects around it. However, unfortunately, most consumer-oriented robots nowadays are either just toys or very experimental or focus on specific functionalities and they are robots like factory arms or medical robots. They can interact with the environment and operating tools but they’re really operated by humans so human controls every move or they just play back a pre-programmed trajectory. They don’t really understand the environments and they cannot move autonomously.
Lilian Weng: In our projects, we’re taking a small step towards this goal and in this we try to teach a human-like robot hand to do in-hand manipulation by moving the objects. This is a six-phase block with OpenAI letters on it, move that to a target orientation. We believe this is an important problem because a human-like robot hand, it’s a universal effort. Imagine we can control that really well, we can potentially automate a lot of tasks that are currently done by human. Unfortunately, not a lot of progress have been made on human-like robot hand due to the complexity of such a system.
Lilian Weng: Why it is hard? Okay. First of all, the system has very high dimensionalities. For example, in our robot, which is as you can see this cool illustration. Shadow dexterity hand, it has 24 joints and 20 actuators. The task is especially hard because during the manipulation, a lot of observations are occluded and they can be noisy. For example, your sensor reading can be wrong and your sensor reading can be blocked by the object itself. Moreover, it’s virtually impossible to simulate your physical world 100% correctly.
Lilian Weng: Our approach for tackling this problem is to use reinforcement learning. We believe it is a great approach for learning how to control robots given that we have seen great progress and great success in many applications by reinforcement learning. You heard about OpenAI Five, the story of point AlphaGo and it will be very exciting to see how reinforcement learning can not only interact with this virtual world but also have an impact on our physical reality.
Lilian Weng: There is one big drawback of reinforcement learning model. In general, today, most of the models are not data efficient. You need a lot of training sample in order to get a good model trained. One potential solution is you build a robot farm. You just collect all the data in parallels with hundreds of thousands of robots but imagine just given how fragile a robot can be. It is very expensive to build and maintain. If you think of another problem, a new problem, or you want to work with new robots, it’s very hard to change. Furthermore, your data can get invalidated very quickly due to small changes in your robot status.
Lilian Weng: As that, we decided to take the sim2real approach, that is you train your model every single simulation but deploy that on physical robots. Here shows how we control the hand simulation. The hand is moving the object to a target orientation. The target is shown on the right so whenever the hand achieved the goal, we just sample a new goal. It just keeps on doing that and we cap the number of success at 50.
Lilian Weng: This is our physical setup. Everything is mounted in this giant metal cage. It’s like this big. The hand is mounted in the middle. It’s surrounded with a motion caption system. It’s actually the system that people use for filming special effects films, like the actor has dots on their bodies, kind of similar. This system tracks the five fingertip positions in the 3D space. We also have three high-resolution cameras for capturing images as input to our vision model. Our vision model predicts positional orientation of the block. However, our proposal sim2real approach might fail dramatically because there are a lot of model difference between simulation and reality. If your model all refer to the simulation, it can perform super poorly, the real robots.
Lilian Weng: In order to overcome this problem, we decided to take … we use reinforcement learning, okay. We train everything simulations so that we can generate technically, theoretically infinite amount of data. In order to overcome the sim2real difference, we use domain randomization.
Lilian Weng: Domain randomization refer to an idea of randomized different elements in simulation so that your policy can be exposed to a variety of scenarios and learn how to adapt. Eventually, we expand the policy to able to adapt to the physical reality.
Lilian Weng: Back in … This idea is relative news. I think they first proposed it in 2016. The researchers try to train a model to control drone like fly across furnitures or the indoor scenarios. They randomized the colors and texture of the walls and furnitures and without seeing any real-world images, they show that it performs pretty well in reality.
Lilian Weng: At OpenAI, we use the same approach to train a better model to protect the position orientation of the objects. As you can see some of the randomization looks totally unrealistic but somehow it worked very well when we feed the model with real images. Later, we also showed that you can randomize all the physical dynamics in simulations and this robot trained with domain randomization worked much better than the one without.
Lilian Weng: Let’s see the results. Okay. I’m going to click the … You really struggle a little bit at the first goal. Yes, okay. The ding indicates one success. This video will keep on going until goal 50 so it’s very, very long but I personally found it very soothing to look at it. I love it.
Lilian Weng: I guess that’s enough. This is our full setup of the training so in the box A, we generate a large number of environments in parallels in which we randomize the physical dynamics and the visual appearance. Based on those, we train two models independently. One is a policy model which takes in the fingertip position and object pose and the goal and output, a desired joint position of the hand so that we can control the hand. Another model is the vision that takes in three images from different camera angles and output the position orientation of the object.
Lilian Weng: When we deploy this thing into the real world, we combine the vision prediction based on the real images together with a fingertip position tracked by the motion capture system and feed that into our policy control model and output action so that then we just send it to the real robot and everything starts moving just like the movie shown. When we train our policy control model, we’ve randomized all kinds of physical parameter in the simulator such as masses, friction coefficient, motor gain, damping factor, as well as noise on the action, on observation. For a revision model, we randomized camera position, lighting, material, texture, colors, blah, blah, blah, and it just worked out.
Lilian Weng: For our model’s architecture, I’ll just go very quickly here. The policy, it’s a pretty simple recurrent unit. Has one layer of really connective layer and the LSTM. The vision model is a straightforward, multi-camera setup. All the three cameras share this RestNet stack and followed by a spatial softmax.
Lilian Weng: Our training framework is distributed and synchronized PBO, proximal policy optimization model. It’s actually the same framework used for training OpenAI Five. Our setup allowed us to generate about two years simulated experience per hour, which corresponds to 17,000 physical robots, so the gigantic robot factory and simulation is awesome.
Lilian Weng: When we deploy our model in reality, we noticed a couple of strategies learned by the robot like finger pivoting, sliding, finger gaiting. Those were also commonly used by human and interestingly, we never explicitly give it words or encouraged those strategies. They would just emerge autonomously.
Lilian Weng: Let’s see some numbers. In order to compare different versions of models, we deployed the models on the real robots and count how many successes the policy can get up to 50 before it dropped the block or time out. We first tried to deploy a model without randomization at all. It got a perfect performance in simulation but look, you can see it’s zero success median. Super bad on the real robot.
Lilian Weng: Then we’re adding domain randomization. The policy becomes much better because 13 success medians, maximum 50. Then we used RGB cameras in our vision model to track the objects. The performance only dropped slightly, still very good. The last one, I think this one’s very interesting because I just mentioned that our policies are recurrent units so like LSTM, it has internal memories.
Lilian Weng: Well, interesting, see how important this memory is so we replaced this LSTM policy with a FIFO or NAS and deployed that on robot and the performance dropped a lot, which indicates that memory play an important role in the sim2real transfers. Potentially, the policy might be using the memory and try to learn how to adapt.
Lilian Weng: However, training in randomized environments does come with a cost. Here we plot the number of success in simulation as a function of simulated experiencing measured in year. If you don’t apply randomization at all, the model can learn to achieve 40 success with about three years simulated experience but in order to get to same number like 40 success in a fully randomized environment took 100 years.
Lilian Weng: Okay, to quick summary. We’ve shown that this approach, reinforcement learning plus training simulation plus domain randomization worked on the real robot and we would like to push it forward. Thank you so much. Next one is Christine.

Research Scientist Christine Payne on the Music Generation team gives a talk on how MuseNet pushes the boundaries of AI creativity, both as an independent composer, and as a collaboration tool with human artists. Erica Kawamoto Hsu / Girl Geek X
Christine Payne: Thank you. Let’s see. Thank you. It’s really great to see all of you here. After this talk, we’re going to take a short break and I’m looking forward to hopefully getting to talk to a lot of you at that point. I’ve also been especially asked to announce that there are donuts in the corner and so please help us out eating those.
Christine Payne: If you’ve been following the progress of deep learning in the past couple years, you’ve probably noticed that language generation has gotten much, much better, noticeably better in the last couple of years. But as a classical pianist, I wondered, can we take the same progress? Can we apply instead to music generation.
Christine Payne: Okay, I’m not Mira. Sorry. Hang on. One moment, I think we’re on the wrong slide deck. All right, sorry about that. Okay, trying again. Talking about music generation. You can imagine different ways of generating music and one way might be to do a programmatic approach where you say like, “Okay, I know that drums are going to be a certain pattern. Harmonies usually follow a certain pattern.” You can imagine writing rules like that but there’s whole areas of music that you wouldn’t be able to capture with that. There’s a lot of creativity, a lot of nuance, the sort of things that you really want a neural net to be able to capture.
Christine Payne: I thought I would dive right in by playing a few examples of MuseNet, which is this neural net that’s been trained on this problem of music generation. This first one is MuseNet trying to imitate Beethoven and a violin piano sonata.
Christine Payne: It goes on for a while but I’ll cut it off there. What I’m really trying to go with in this generation process is trying to get long-term structure so both the nuance and the intricacies of the pieces but also something that stays coherent over a long period of time. This is the same model but instead trying to imitate jazz.
Christine Payne: Okay, and I’ll cut this one off too. As you maybe could tell from those samples, I am more interested in the problem of composing the pieces themselves, so sort of where the notes should be and less in the actual quality of the solemnness and the timbre. I’ve been using a format that’s called MIDI which is an event-based system of writing music. It’s a lot like how you would write down notes in a music score. Like this note turns on at this moment in time played by this instrument maybe at this volume but you don’t know like this amazing cellist actually made it sound this way so I’m throwing out all of that kind of information.
Christine Payne: But the advantage of throwing that out is then you can get this longer-term structure. To build this sort of dataset, it involves a little bit of begging for data. I’ve had a bunch of people like BitMidi and ClassicalArchives were nice enough to just send me their collections and then a little bit of scraping and also MAESTRO’s Google Magenta’s dataset and then also a bunch of scraping online sets.
Christine Payne: The architecture itself, here I’m drawing really heavily from the way we do language modeling and so we use a specific kind of neural net that’s called a transformer architecture. The advantage of this architecture is that it’s specifically good at doing long-term structure so you’re able to look back not only at things that have happened in the recent past but really, you can look back like what happened in the music a minute ago or something like that, which is not possible with most other architectures.
Christine Payne: In the language world, I’d like to think of this, the model itself is trained on the task of what word is going to come next. It might initially see just like a question mark so it knows it’s supposed to start something. In English, we know like maybe it’s the or she or how or some like that. There’s some good guesses and there’s some like really bad guesses. If we know now the first word is hello then we’ve kind of narrowed down what we expect our next guesses should be. It might be how, it might be my, it’s probably not going to be cat. Maybe it could be cat. I don’t know.
Christine Payne: At this point, we’re getting pretty sure–like a trained model should actually be pretty sure that there should be a good 90% chance the next word is name and now it should be like really 100% sure or like 99.5% sure or whatever that the next word is going to be is. Then here we hit kind of an interesting branching point where there are tons of good answers so lots of names could be great answers here, lots of things could also be really bad answers so we don’t expect to see like some random verbs, some random … There are lots of things that we think would be bad choices but we get a point here to branch in good directions.
Christine Payne: The idea is once you have a model that’s really good at this, you can then turn it into a generator by sampling from the model according to those probabilities. The nice thing is you get the coherent structure. When you get a moment like this, you know like I have to choose … In music, it’s usually like I have to choose this rhythm, I have to choose … like if I choose the wrong note, it’s just going to sound bad, things like that. But then there are also a lot of points like this where the music can just go in fun and interesting different directions.
Christine Payne: But of course, now we have the problem of how do you translate words, how do you translate this kind of music into a sequence of words that the model can do. The system that I’m using is very similar to how MIDI itself works. I have a series of tokens that the model will always we see. Initially, it’ll always see the composer or the band or whoever wrote the piece. It’ll always see what instrument to expect in the piece or what set of instruments.
Christine Payne: Here, it sees the start token because it’s at the start of this particular piece and a tempo. Then as the piece begins, we have a symbol that this C and that C each turn on with a certain volume and then we have a token that says to wait a certain amount of time. Then as it moves forward, the volume zero means that first note just turned off and the G means the next note turns on. I think we have to wait and similarly, here the G turns off, the E turns on and we wait. You can just progress through the whole set of music like this.
Christine Payne: In addition to this token by token thing, I’m helping the model out a little bit by giving it a sense of the time that’s going on. I’m also giving it an extra embedding that says everything that happens in this purple line happens in the same amount of time or at the same moment in time. Everything in blue is going to get a different embedding that’s a little bit forward in time and so forth.
Christine Payne: The nice thing about an embedding or a system like this is that it’s pretty dense but also really expressive. This is the first page of a Chopin Ballade that is like actually encapsulates how the pianist played it, the volumes, the nuances, the timings, everything like that.
Christine Payne: The model is going to see that sequence of numbers like that. Like that first 1444 I think means it must mean Chopin and the next one probably means piano and the next one means start, that sort of thing. The first layer for the model, what it has to do is it needs to translate that number into a vector of numbers and then it can sort of learn a good vector that’ll represent so it’ll get a sense of like this is what it means to be Chopin or this is what it means to be like a C on a piano.
Christine Payne: The nice thing you can do once … The model will learn. Like initially it starts out with a totally random sense so it has no idea what those numbers should be but in the course of training, it’ll learn better versions of that. What you can do is you can start to map out what it’s learned for these embeddings. For example, this is what it’s learned for a piano scale like all the notes on a piano and it’s come to learn that like all of these As are kind of similar, that the notes relate to each other. This is like moving up on a piano. It’s hard to tell here but it’s learned little nuances like up a major third is closer than like up a tritone or stuff like that. Like actually really interesting musical stuff.
Christine Payne: Along with the same thing, given the fact that I’m always giving it this genre token and then the instrument token, you can look at the sort of embeddings it’s learned for the genres itself. Here, the embedding it’s learned for all these French composers. Ends up being pretty similar. I actually like that Ravel wrote like in the style of Spanish pieces and then there’s the Spanish composer that’s connected to him so like it makes a lot of good sense musically. Similarly, like over in the jazz domain, a lot of the ones. I think there are a couple of random ones that made no sense at all. I can’t remember now off the top of my head. It’s like Lady Gaga was connected to Wagner or something like but mostly, it made a lot of great sense.
Christine Payne: The other kind of fun thing you can do once you have the style tokens is you can try mismatching them. You can try things like literally taking 0.5 of the embedding for Mozart plus 0.5 of the embedding of jazz and just like adding them together and seeing what happens or in this case what I’m doing is I’m giving it the token for Bon Jovi, instruments for bands, but then I’m giving it the first six notes of a Chopin Nocturne. Then the model just has to generate as best it can at that point.
Christine Payne: You’ll hear at the start of this, it’s very much how the Chopin Nocturne itself sounds. I’ve cut off the very, very beginning of it but you’ll hear–so that left-hand pattern is going to be like straight out of Chopin and then well, you’ll see what happens.
Christine Payne: Sorry, it’s so soft but it gets very Bon Jovi at this point, the band kicks in. I always loved it like Chopin looks a little shocked but I really love that it manages to keep the left-hand pattern of the Nocturne going even though it’s like now thinks it’s in this pop sort of style.
Christine Payne: The other thing I’ve been interested in this project is in how musicians and everyone can use generators like this. If you go to our OpenAI blog you can actually play with the model itself. We’ve created, along with Justin and Eric and Nick, a sort of prototype tool of how you might co-compose pieces using this model. What you can do is you can specify the style and the instruments, how long a segment you want the model to generate and you hit start and the model will come back with four different suggestions of like how you might begin a piece in this style. You go through and you pick your favorite one, you hit the arrow again to keep generating and the model will come up with four new different ways. You can continue on this way as long as you want.
Christine Payne: What I find kind of fun about this is you’re actually really … like it feels like I’m composing but not at a note by note level and so I was really interested in how humans will be able to, and musicians will be able to guide composing this way. Just kind of wrapping up, I thought I would play an example of … This is one guy who took both GPT-2 to write the lyrics, which I guess is hence the Covered in Cold Feet and then MuseNet to do the music. It’s a full song but I’ll just play the beginning of it that he then recorded himself.
Christine Payne: (singing)
Christine Payne: Visit the page to hear the whole song but it’s been really fun to see those versions. The song, I ended up singing it the entire day. It gets really catchy but it’s been really fun to see musicians start to use it. People have used it to finish composing symphonies or to write full pieces, that sort of thing.
Christine Payne: In closing, I just wanted to share I’ve gone through this crazy path of two years ago being a classical pianist to now doing AI research here and I just wanted to … I didn’t know that Rachel was going to be right here. Give a shout out to fast.ai. She’s the fast.ai celebrity here but yeah. This has been my path, been doing it. These are the two courses I particularly love, fast.ai and deeplearning.ai and then I also went through OpenAI’s Scholars program and then the Fellows Program. Now I’m working here full-time, but happy to talk to anybody here if they’re interested in this sort of thing.
Christine Payne: The kind of fun thing about AI is that there’s so much that’s still wide open and it’s really helpful to come from different backgrounds where you bring a … It’s amazing how if you bring a new perspective or a new insight, there are a lot of things that are still just wide open that you can figure out how to do. I encourage anyone to come and check it out. We’ll have a concert. Thank you.

RL Team Manager Mira Murati gives a talk about reinformatiion learning and industry trends at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Mira Murati: Hey, everyone, I’m Mira Murati and I’ll talk a little bit about the advancements in reinforcement learning from the lens of our research team here at OpenAI. Maybe I’ll kick things off by just telling you a bit about my background and how I ended up here.
Mira Murati: My background is in mechanical engineering but most of my work has been dedicated to practical applications of technology. Here at OpenAI, I work on Hardware Strategy and partnerships as well as managing our Reinforcement Learning research team alongside John Schulman, who is our lead researcher. I also manage our Safe Reinforcement Learning team.
Mira Murati: Before coming to OpenAI, I was leading the product and engineering teams at Leap Motion, which is a company that’s focused on the issue of human machine interface. The challenge with the human machine interface, as you know, is that we’ve been enslaved to our keyboard and mouse for 30 years, basically. Leap Motion was trying to change that by increasing the bandwidth of interaction with digital information such that, just like you see here, you can interact … Well, not here, with the digital space in the same natural and high bandwidth way that you interact with your physical space. The way you do that is using computer vision and AI to track your fingers in space and bring that input in virtual reality or augmented reality in this case.
Mira Murati: Before that, I was at Tesla for almost three years leading the development and launch of the Model X. That’s enough about me. I’ll touch a bit about on the AI landscape as a whole, just to offer a bit of context on the type of work that we’re doing with our Reinforcement Learning team. Then I’ll talk a bit about the impact of this work, the rate of change in the field as well as the challenges ahead.
Mira Murati: As you know, the future has never been bigger business. Every day we wake up to headlines like this and a lot of stories talking about the ultimate conversions where all the technologists come together to create the ultimate humankind dimension, that of general artificial intelligence. We wonder what this is going to do to our minds and to our societies, our workplaces and healthcare. Even politicians and cultural commentators are aware of what’s happening with AI to some extent, and politicians like this, to the extent that there’s a lot of nations out there that have published their AI strategies.
Mira Murati: There is definitely a lot of hype, but there is also a ton of technological advancement that’s happening. You might be wondering what what’s driving these breakthroughs. Well, so a lot of advancements in RL are driving the field forward and my team is working on some of these challenges through the lens of reinforcement learning.
Mira Murati: Both Brooke and Lilian did a great job going over reinforcement learning so I’m not going to touch too much upon that, but basically, to reiterate, it is you’re basically learning through trial and error. To provide some context for our work, I want us to take a look at …
Mira Murati: Oh, okay. There’s music. I wanted to take a look at this video where first you see this human baby, nine months old, how he is exploring the environment around him. You see this super high degrees of freedom interaction with everything around him. I think this is four hours of play in two minutes. In some of the things that this baby does like handling all these subjects, rolling around all this stuff, this is almost impossible for machines to do as you saw from Lilian’s talk.
Mira Murati: Then … Well, he’s going to keep going, but let’s see. Okay, now that … What I want to show you is … Okay, this is not working, but basically, I wanted you to show you that by contrast, so you have this video game over there where you would see this AI agent that’s basically trying to cross this level and makes the same mistakes over and over again. The moral of the story is that AI agents are very, very limited when they’re exploring their environment. Human babies just nine months old have this amazing ability to explore their environment.
Mira Murati: The question is, why are humans so good at understanding the environment around them? Of course, humans … We have this baby running in the playground. Of course, humans are very good at transferring knowledge from one domain to another, but there is also prior knowledge from evolution and also, from your prior life experiences. For example, if you play a lot of board games and I asked you to play a new one that you have never seen before, you’re probably not going to start learning that new game from scratch. You will apply a lot of the heuristics that you have learned from the previous board game and utilize those to solve this new one.
Mira Murati: It’s precisely this ability to abstract, this conceptual knowledge that’s based on or learned from perceptual details of real life that’s actually a key challenge for our field right now and we refer to this as transfer learning.
Mira Murati: What’s the state of things? There’s been a lot of advancements in machine learning and particularly in reinforcement learning. As you heard from the talks earlier, new datasets drive a lot of the advancements in machine learning. Our Reinforcement Learning team built a suite of games, thousands of games, that in itself you think playing video games is not so useful, but actually, they’re a great test bed because you have a lot of problem-solving and also content that’s already there. It comes for free in a way.
Mira Murati: The challenge that our team has been going after is how can we solve a previously unseen game as fast as a human, or even faster, given prior experiences with similar games. The Gym Retro dataset helps us do that. I was going to say that some of the games look like this but the videos are not quite working. But in a way, the Gym Retro dataset, you can check it out on the OpenAI blog, emphasizes the weaknesses of AI which is that of grasping a new task quickly and the ability to generalize knowledge.
Mira Murati: Why do all these advancements matter and what do the trends look like? It’s now just a bit over 100 years after the birth of the visionary mathematician Alan Turing and we’re still trying to figure out how hard it’s going to be to get to general artificial intelligence. Machines have surpassed us at very specific tasks but the human brain sets a high bar for what’s AI.
Mira Murati: In the 1960s and ’70s, this high bar was a game of chess. Chess was long considered the summit of human intelligence. It was visual, tactical, artistic, intelligence, mathematical, and chess masters could remember every single game that they played, not to mention that of their competitors, and so you can see why chess became such a symbol of mastery or a huge achievement of the human brain. It combined insight and forward planning and calculation, imagination, intuition, and this was until 1996, when the Deep Blue machine, chess machine from IBM was able to beat Garry Kasparov. If you had brought someone from the 1960s to that day, they would be completely astonished that this had happened but in 1996, this did not elicit such a reaction because in a way, Deep Blue had cheated by utilizing the power of hardware of Moore’s law. It leveraged the advancements in hardware to beat Garry Kasparov at chess.
Mira Murati: In a way, this didn’t show so much the advancements in AI, but rather that chess was not the pinnacle of human intelligence. Then the human sights were set on the Chinese game of Go, which is much more complex and just with brute force, you’d be quite far from solving Go, the game of Go with brute force and where we stand with hardware today. Then of course, in 2016, we saw the DeepMind’s AlphaGo beat Lee Sedol in Korea and that was followed by advancements in AlphaGo Zero. OpenAI robotics team of course, used some of the algorithms developed in the RL team to manipulate the cube and then we saw very recently, obviously, the Dota 5v5 beat the world champions.
Mira Murati: There’s been a very strong accelerating trend of advancements pushed by reinforcement learning in general. However, there’s still a long way to go. There are a lot of questions with reinforcement learning and in figuring out where the data is coming from and what actions do you take early on that get you the reward later. Also issues of safety, how do you learn in a safe way and also how do you continue to learn once you’ve gotten really good? Think of self-driving cars, for example. We’d love to get more people thinking about this type of challenges and I hope that some of you will join us in doing so. Thank you.

Research Scientist Amanda Askell on the Policy team gives a talk on AI policy at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Amanda Askell: Okay, can everyone hear me? Cool. We’ve had like a lot of talks on some of the technical work that’s been happening at OpenAI. This talk is going to be pretty introductory because I guess I’m talking about what is quite a new field, but as Ashley said at the beginning, it’s one of the areas that OpenAI focuses on. This is a talk on AI policy and I’m a member of the policy team here.
Amanda Askell: I realize now that this picture is slightly unfortunate because I’m going to give you some things that look like they’re being produced by a neural net when in fact this is just an image because I thought it looked nice.
Amanda Askell: The core claims behind why we might want something like AI policy to exist in the world are really simple. Basically, AI has the potential to be beneficial. Hopefully, we can agree with this. We’ve had lots of talks showing how excellent AI can be and things that it can be applied to. AI also has the potential to be harmful so I’ll talk a little bit about this in the next slide but you know we hear a lot of stories about systems that just don’t behave the way that they’re creators intended to when they’re deployed in the world, systems that can be taken over by people who want to use them for malicious purposes. Anything that has this ability to do great things in the world can also be either misused or lead to accidents.
Amanda Askell: We can do things that increase the likelihood that AI will be beneficial so hopefully, that’s also fairly agreed-upon. But also that this includes making sure that the environment the AI is developed in is one that incentivizes responsible development. They’re like nontechnical things that we can do to make sure that AI is beneficial.
Amanda Askell: I think these are all like really simple and this leads to this idea that we should be doing some work in known technical fields just to make sure that AI is developed responsibly and well. Just to like kind of reiterate the claims of the previous slide, the potential benefits of AI are obviously kind of huge and I feel like to this audience I don’t really need to sell them but we can go over them. You know language models provide the ability potentially to assist with writing and other day-to-day tasks.
Amanda Askell: We can see that we can apply them to large complex problems like climate change potentially. This is the kind of like hope for things like a large scale ML. We might be able to enable like innovations In healthcare and education so we might be able to use them for things like diagnosis or finding new treatments for diseases. Finally, they might drive the kind of economic growth that would reduce the need to do work that people don’t find fulfilling. I think this is probably controversial. This is one thing that’s highly debated in AI ethics but I will defend it. I’ve done lots of unfulfilling work in my life and if someone could just pay me to not do that, I would have taken that.
Amanda Askell: Potential harms like language models of the same sort could be used to like misinform people by malicious actors. There are concerns about facial recognition as it improves and privacy. People are concerned about automation and unemployment if it’s not dealt with well. Like does this just lead to massive unfairness and inequity? Then people are also worried about things like decision making and bias. We already see in California that there’s ML systems being used for things like decisions about bail being set but also historically, we’ve used a lot of systems for things like whether someone gets credit. I mean so whether your loan’s approved or not given that there’s probably a huge amount of bias in the data and that we don’t know yet how to completely eliminate that, this could be really bad and it could increase systemic inequity in society, so that’s bad.
Amanda Askell: We’re also worried about like AI weapons and global security. Finally, just like a general misalignment of future AI systems. A lot of these are just like very classic examples of things that people are thinking about now, but this should just … We could expect this to be the sort of problems that we just see on an ongoing basis in the future as systems get more powerful.
Amanda Askell: I don’t think AI is like any different from many other technologies in at least some respects here. How do we avoid building things that are harmful? Doing the same kind of worries just apply to like the aviation industry. Planes can also be taken over by terrorists. Planes can be built badly and lead to accidents. The same is true of like cars or pharmaceuticals or like many other technologies with the potential to do good, it can end up … There can be accidents. It can be harmful.
Amanda Askell: In other industries we invest in safety, we invest in reducing accidents, we invest in security, so that’s like reducing misuse potential, and we also invest in social impact. In case of aviation, we know are concerned about things like the impact that flying might have on the climate. This is like the kind of third sort of thing that people invest in a lot.
Amanda Askell: All of this is very costly so this is just a kind of intro to like one way in which we might face problems here. I’m going to use a baking analogy, mainly because I was trying to think of a different one and I had used this one previously and I just couldn’t think of a better one.
Amanda Askell: The idea is, imagine you’ve got a competition and the nice thing about baking competitions, maybe I just have watched too many of them, is like you care both about the quality of what you’re creating and also about how long it takes to create it. Imagine a baking competition where you can just take as much time as you want and you’re just going to be judged on the results. There’s no race, like you don’t need to hurry, you’re just going to focus purely on the quality of the thing that you’re creating.
Amanda Askell: But then you introduce this terrible thing, which is like a time constraint or even worse, you can imagine you make it a race. Like the first person to develop the bake just gets a bunch of extra points. In that case, you’re going to be like well, I’ll trade off some of the quality just to get this thing done faster. You trade off some quality for increased speed.
Amanda Askell: Basically, we can expect something similar to happen with things like investment in areas like the areas that I talked about in the previous slide, where it’s like it might be that I would want to just like continue investing and making sure that my system is secure essentially like forever. I just never want someone to misuse this system so if I was given like 100 years, I would just keep working on it. But ultimately, I need to produce something. I do need to put something out into the world and the concern that we might have is that competition could drive down the incentive to invest that much in security.
Amanda Askell: This, again, happens across lots of other industries. This is like not isolated to AI and so there’s a question of like, what happens here? How do we ensure that companies invest in things like safety? I’m going to argue that there are four things. Some of the literature might not mention this one but I think it’s really important. The first one is ethics. People and companies are surprisingly against being evil. That’s good, that’s important. I think this gets not talked about enough. Sometimes we talk like the people that companies would just be totally happy turning up at like 9:00 a.m. to build something that would cause a bunch of people harm. I just don’t think that people think like that. People are … I have fundamental faith in humanity. I think we’re all deeply good.

Software Engineer Chloe Lin listens to the OpenAI Girl Geek Dinner speakers answer audience questions. Photo credit: Erica Kawamoto Hsu / Girl Geek X
Amanda Askell: It’s really great to align your incentives with your ethical beliefs and so regulation is obviously one other component that’s there to do that. We create these regulations and industry norms to basically make sure that if you’re like building planes and you’re competing with your competitor, you still just have to make your planes. You have to establish that they reach some of … Tripped over all of those words.
Amanda Askell: You have to establish that they reach some level of safety and that’s what regulation is there for. There’s also liability law and so companies have to compensate who are harmed by failures. This is another thing that’s driving that incentive to make sure your bake is not going to kill the judges. Well, yeah, everyone will be mad at you and also, you’ll have to pay a huge amount of money.
Amanda Askell: Finally, the market. People just want to buy safe products from companies with good reputations. No one is going to buy your bake if they’re like, “Hang on, I just saw you drop it on the floor before you put it into the oven. I will pay nothing for this.” These are four standard mechanisms that I think are used to like ensure that safety is like pretty high even in the cases of competition between companies in other domains like aviation and pharmaceuticals.
Amanda Askell: Where are we with this on AI? I like to be optimistic about the ethics. I think that coming to a technology company and seeing the kind of tech industry, I’ve actually been surprised by the degree to which people are very ethically engaged. Engineers care about what they’re building. They see that it’s important. They generally want it to be good. This is more like a personal kind of judgment on this where I’m like actually, this is a very ethically engaged industry and that’s really great and I hope that continues and increases.
Amanda Askell: With regulation, currently there are not many industry-specific regulations. I missed an s there but speed and complexity make regulation more difficult. The idea is that regulation is very good when there’s not an information asymmetry between the regulator and the entity being regulated. It works much less well when there is a big information asymmetry there. I think in the case of ML, that does exist. It’s very hard to both keep up with like, I think for regulators keeping up with contemporary ML work is really hard and also, the pace is really fast. This makes it actually quite difficult as an area to build very good regulation in.
Amanda Askell: Liability law is another thing where it’s just like a big question mark because like for ML accidents and misuse, in some cases it’s just unclear what existing law would say. If you build a model and it harms someone because it turns out that there was data in the model that was biased and that results in a loan being denied to someone, who is liable for that harm that is generated? You get easier and harder cases of this, but essentially, a lot of the kind of … I think that contemporary AI actually presents a lot of problems with liability law. It will hopefully get sorted out, but in some cases I just think this is unclear.
Amanda Askell: Finally, like market mechanisms. People just need to know how safe things are for market mechanisms to work well. In the case of like a plane, for example, I don’t know how safe my planes are. I don’t go and look up the specs. I don’t have the engineering background that would let me actually evaluate, say, a new plane for how safe it is. I just have to trust that someone who does know this is evaluating how safe those planes are because there’s this big information gap between me and the engineers. This is also why I think we shouldn’t necessarily expect market mechanisms to do all of the work with AI.
Amanda Askell: This is to lead up to this … to show that there’s a broader problem here and I think it also applies in the case of AI. To bring in a contemporary example, like recently in the news, there’s been concern. Vaping is this kind of like new technology that is currently not under the purview of the FDA or at least generally not heavily regulated. Now there’s concern that it might be causing pretty serious illnesses in people across the US.
Amanda Askell: I think this is a part of a more broad pattern that happens a lot in industries and so I want to call this the reactive route to safety. Basically, a company does the thing, the thing harms people. This is what you don’t want on your company motto. Do the thing. The thing harms people. People stop buying it. People sue for damages. Regulators start to regulate it. This would be really uninspiring as your company motto.
Amanda Askell: This is actually a very common route to making things more safe. You start out and there’s just no one who’s there to make sure that this thing goes well and so it’s just up to people buy it, they’re harmed, they sue, regulators get really interested because suddenly your product’s clearly harming people. Is this a good route for AI? Reasons against hope … I like the laugh because I’m like hopefully, that means people agree like no, this would be terrible. I’m just like well, one reason, just to give like the additional things of like obviously that’s kind of a bad way to do things anyway.
Amanda Askell: AI systems can often be quite broadly deployed almost immediately. It’s not like you just have some small number of people who are consuming your product who could be harmed by it in a way that a small bakery might. Instead, you could have a system where you’re like I’ve built the system for determining whether someone should get a loan. In principle, almost every bank in the US could use that the next day and that’s –The potential for widespread deployment makes it quite different from technologies where you just have a really or like any product where you have just like a small base of people.
Amanda Askell: They have the potential for a really high impact. The loan system that I just talked about could, basically, could in principle really damage the lives of a lot of people. Like apply that to things like bail systems as well, which we’re already seeing and even potentially with things like misinformation systems.
Amanda Askell: Finally, in a lot of cases it’s just difficult to attribute the harms and if you have something that’s spreading a huge amount of misinformation, for example, and you can’t directly attribute it to something that was released, this is concerning because it’s not like this route might work. This route actually requires you to be able to see who caused the harm and whenever that’s not visible, you just don’t expect this to actually lead to good regulation.
Amanda Askell: Finally, I just want to say I think there are alternatives to this reactive break things first approach in AI and this is hopefully where a lot of policy work can be useful.
Amanda Askell: Just to give a brief overview of policy work at OpenAI. I think I’m going to start with the policy team goals just to give you the sense of what we do. We want to increase the ability of society to deal with increasingly advanced AI technology, both through information and also through pointing out mechanisms that can make sure that technology is safe and secure and that it does have a good social impact. We conduct research into long-term issues related to AI and AGI so we’re interested in what happens when these systems become more powerful. Not merely reacting to systems that already exist, but trying to anticipate what might happen in the future and what might happen as systems get more powerful and the kind of policy problems and ethical problems that would come up then.
Amanda Askell: Finally, we just help OpenAI to coordinate with other AI developers, civil society, policymakers, et cetera, around this increasingly advanced technology. In some ways trying to break down these information asymmetries that exist and it can cause all of these problems.
Amanda Askell: Just to give a couple of examples of recent work from the teams to the kind of thing that we do. We released a report recently with others on publication norms and release strategies in ML. Some of you will know about like the GPT-2 language release and the decision to do staged release. We discussed this in the recent report. We also discussed other things like the potential for bias in language models and some of the potential social impacts of large language models going forward.
Amanda Askell: We also wrote this piece on cooperation and responsible AI development. This is related to the things I talked about earlier about the potential for competition to push this bar for safety too low and some of the mechanisms that can be used to help make sure that that bar for safety is raised again.
Amanda Askell: Finally, since this is an introduction to this whole field, which is like new and emerging field, here are examples of questions I think are really interesting and broad but can be broke down to these very specific applicable questions. What does it mean for AI systems to be safe, secure, and beneficial and how can we measure this? This includes a lot of traditional AI ethics work, like my background is in ethics. A lot of these questions about like how you make a system fair and what it means for a system to be fair. I would think of that as falling under the what is it for a system to be socially beneficial, and I think that work is really interesting. I do think that there’s just this broad family of things there are like policy and ethics and governance. I don’t think of these as separate enterprises.
Amanda Askell: Hence, this is an example of why. What are ways that AI systems could be developed that could be particularly beneficial or harmful? Again, trying to anticipate future systems and ways that we might just not expect them to be harmful and they are. I think we see this with the existing technology. Maybe it’s like trying to anticipate the impact that technology will have is really hard but like given the huge impact that technology is now having, I think trying to do some of that research in advance is worthwhile.
Amanda Askell: Finally, what can industry policymakers and individuals do to ensure that AI is developed responsibly? This relates to a lot of the things that I talked about earlier, but yeah, what kind of interventions can we have now? Are there ways that we can inform people that would make this stuff all go well?
Amanda Askell: Okay, last slide except the one with my email on it, which is the actual last slide. How can you help? I think that there’s this interesting, this is just like … I think that this industry is very ethically engaged and in many ways, it can feel like people feel like they need to do the work themselves. I know that a lot of people in this room are probably engineers and researchers. I think the thing I would want to emphasize is, you can be really ethically engaged and that doesn’t mean you need to take this whole burden on yourself.
Amanda Askell: One thing you can also do is advocate for this work to be done, either in your company, or just anywhere where people are like … in your company, in academia or just that your company is informed of this stuff. But in general, helping doesn’t necessarily have to mean taking on this massive burden of learning an entire field yourself. It can just mean advocating for this work being done. At the moment, this is a really small field and I would just love to see more people working in it. I think advocacy is really important but I also think another thing is you can technically inform people who are working on this.
Amanda Askell: We have to work closely with a lot of the teams here and I think that’s really useful and I think that policy and ethics work is doing its best, basically, when it’s really technically informed. If you find yourself working in a position where a lot of the things that you’re doing feel like they are important and would benefit from this sort of work, like helping people who are working on it is a really excellent way of helping. It’s not the only thing that you can do is spend half of your time doing the work that I’m doing and the others on the team are doing. You can also get people like us to do it. We love it.
Amanda Askell: If you’re interested in this, so thank you very much.

OpenAI girl geeks: Brooke Chan, Amanda Askell, Lilian Weng, Christine Payne and Ashley Pilipiszyn answer questions at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Audience Member: I have a question.
Amanda Askell: Yes.
Audience Member: For Amanda.
Amanda Askell: Yes.
Audience Member: Drink your water first. No, I think the ethics stuff is super interesting. I don’t know of a lot of companies that have an ethics department focused on AI, and I guess one thing that I’m curious about is, like you pointed out like your papers but like, and I know you talked about educating and all this other stuff but what are you guys…do? Do you know what I mean? Other than write papers.
Amanda Askell: Yeah.
Ashley Pilipiszyn: Oh, Christine.
Amanda Askell: Which one? Yeah, so I think at the moment there’s like a few kind of rules. I can say what we do but also what I think that people in these roles can do. So in some cases it can be like looking at what you’re building internally. I think we have like the charter and so you want to make sure that everything that you’re doing is in line with the charter. Things like GPT-2 and release decisions, I think of as a kind of like ethical issue or ethical/policy issue where I would like to see the ML community build really good norms there. Even if people don’t agree with what OpenAI try to do with its release decisions, it was coming from a place of trying to build good norms and so you can end up thinking about decisions like that.
Amanda Askell: That’s more of an example of something where you’re like it’s not writing a paper, it’s just like thinking through all of the consequences of different publication norms and what might work and what might not. That’s like one aspect, that’s the kind of like internal component. I think of the external component as like, on the one hand it’s just like writing papers so just being like what are the problems here that people could work on and in a lot ways that’s just like outreach, like trying to get people who are interested in working on this to work on it further. For that, there’s a few audiences, so you might be interested in attracting people to the field if you think that there are these like ongoing problems within both companies and maybe with other relevant actors. Like maybe you also want people going into government on this stuff.
Amanda Askell: But also just like the audience can be internal, to make people aware of these issues and they can also be things like policymakers, just inform of the kind of structure of the problem here. I think of it as having this kind of internal plus external component and you can end up dividing your time between the two of them. We spend some time writing these papers and trying to get people interested in these topics and just trying to solve the problems. That’s the nice thing about papers is you can just be like, what’s the problem, I will try and solve it and I’ll put my paper of an archive. Yeah, and so I think there’s both of those.
Amanda Askell: It’s obviously fine for companies to have people doing both, like if you haven’t and I think it’s like great if a company just has a team that’s just designed to look at what they’re doing internally and if anyone has ethical concerns about it, that team can take that on and own it and look at it. I think that’s a really good structure because it means that people don’t feel like … if you’re like just having to raise these concerns and maybe feel kind of isolated, that’d be bad but if you have people that you know are thinking about it, I think that’s a really good thing. Yeah, internal plus external, I can imagine different companies liking different things. I hope that answers the question.
Rose: My question is also for Amanda. So the Google AI Ethics Board was formed and disbanded very quickly kind of famously within like the span of less than a month. How do you kind of think about that like in the context of the work that OpenAI is doing and like how do you think about like what they failed at and like what we can do better?
Amanda Askell: This was a really difficult case so I can give you … I remember personally kind of looking at this and being like I think that one thing that was in it … I don’t know if people know the story about this case but basically, it was that Google formed a board and they were like, “We want this to be intellectually representative,” and it garnered a lot criticism because it had a person who was head of the Heritage Foundation, so a conservative think-tank in the US, as one of its members, and this was controversial.
Amanda Askell: I remember having mixed views on this, Rose. I do think it’s great to … Ultimately, these are systems that are going to affect a huge number of people and that includes a huge number of people who have views on how they should be used and how they should affect them. They’re just very different from me and I want those people to be represented and I want their views on how they do or do not want systems to affect them to be at the table. We talked earlier about the importance of representativeness and I genuinely believe that for people who have vastly different views for myself. If they’re affected by it, ultimately, their voice matters.
Amanda Askell: At the same time, I think I also … there’s a lot of complicating–you’re getting my just deeply mixed emotions here because I was like, there’s a strange sense in which handpicking people to be in the role of a representative of a group where you’re like, I don’t know, we select who the intellectual representatives are also struck me as somewhat odd. It’s a strange kind of … It set off my old political philosophy concerns where I’m like, “Oh, this just doesn’t …” It feels like it’s imitating democracy but isn’t getting there. I had and I was also just like plus the people who come to the table and there are certain norms of respect to lots of groups of people that just have to be upheld if you’re going to have people with different views have an input on a topic.
Amanda Askell: I think some of the criticisms were that people felt those norms had been upheld and this person had been insulting to key groups of people, the trans community and to immigrants. Largely, mixed feelings where I was just like I see this intention and it actually seems to me to be a good one, but I see all of these problems with trying to execute on it.
Amanda Askell: I can’t give an awesome response to this. It’s just like yeah, here it is, I’ve nailed it. It’s just like yeah, these are difficult problems and I think if you came down really strongly on this where it was like this was trivially bad or you were like this was trivially good, it just feels no, they were just like there are ways that I might have done this differently but I see what the goal was and I’m sympathetic to it but I also see what the problems were and I’m sympathetic to those. Yeah, it’s like the worst, the least satisfying answer ever, I guess.

OpenAI Girl Geek Dinner audience enjoys candor from women in AI. Erica Kawamoto Hsu / Girl Geek X
Audience Member: Hi, I have a question for Brooke. I’m also a fan of Dota and I watched TI for two years. My question is, if your model can already beat the best team in the world, what is your next goal?
Brooke Chan: Currently, we’ve stopped the competitive angle of the Dota project because really what we wanted to achieve was to show that we could get to that level. We could get to superhuman performance on a really complex game. Even at finals, we didn’t necessarily solve the whole game because there were a lot of restrictions, which people brought up. For example, we only used 17 out of the you know 100 and some heroes.
Brooke Chan: From here, we’re just looking to use Dota more as a platform for other things that we want to explore because now we know that it’s something that is trainable and can be reused in other environments, so yeah.
Audience Member: Hi, my question is about what are some of the limitations of training robots in a simulator?
Lilian Weng: Okay, let me repeat. Question is, what’s a limitation of training the robot-controlled models in the simulation? Okay, there are lots of benefits, I would say, because in simulation, you have the ground rules. You know exactly where the fingertips are, you know exactly what’s the joint involved. We can do all kinds of randomization modification of the environment. The main drawback is we’re not sure what’s the difference between our simulated environment and reality. Our eventual goal is to make it work in reality. That’s the biggest problem. That’s also what decides whether our sim2real transfer going to work.
Lilian Weng: I will say one thing that confuse me or puzzles me personally the most is when we are running all kinds of randomizations, I’m not sure whether it’s getting us closer to the reality because we don’t have a good measurement of what the reality looks like. But one thing I didn’t emphasize a lot in the talk is we expect because we design all kinds of environment in the simulation and we asked the policy model to master all of them. There actually emerges some meta learning effect, which we didn’t emphasize but with meta learning, your model can learn how to learn. We expect this meta learning in fact to empower the model to handle something they’d never seen before.
Lilian Weng: That is something we expect with domain randomization that our model can go above what it has seen in the simulation and eventually adapt to the reality. We are working all kinds of technique to make the sim2real thing happen and that’s definitely the most difficult thing for robotics because it’s easy to make things work in simulation. Okay, thanks.
Audience Member: I was just curious as kind of another follow-up question to Brooke’s answer for earlier but for everybody on the panel too. What do you consider to be some of the longer-term visions for some of your work? You did an impressive thing by having Dota beat some real people but where would you like to see that work go or what kinds of problems do you think you could solve with that in the future too, and for some other folks on the panel too?
Brooke Chan: Sure, I would say that pretty honestly when we started the Dota project we didn’t actually know whether or not we would be able to solve it. The theory at the time was that we would need a much more powerful algorithm or a different architecture or something in order to push it kind of all the way. The purpose of the project was really to demonstrate that we could use a relatively straightforward or simple algorithm in order to work on this complex game.
Brooke Chan: I think going out from here, we’re kind of looking into environments in general. We talked about how Dota might be one of our last kind of games because games are still limited. They’re helpful and beneficial in that you can run them in simulation, you can run them faster but we want to kind of also get closer to real-world problems. Dota was one step to getting to real-world problems in the parts that I talked about like the partial information and the large action space and things like that. Going on from there, we want to see what other difficult problems you could also kind of apply this sort of things to. I don’t know if other people …
Christine Payne: Sure. In terms of a music model, I would say kind of two things I find fascinating. One is that I really like the fact that it’s this one transformer architecture which we’re now seeing apply to lots of different domains. The fact that it can both do language and music and it’s really kind of interesting to find these really powerful algorithms that it doesn’t care what it’s learning, it’s just learning. I think that that’s going to be really interesting path going forward.
Christine Payne: Then, also, I think that music is a really interesting test for like we have a lot of sense as humans so we know how we would want the music to go or we know how the music affects us emotionally or there’s all this sort of human interaction that we can explore in the music world. I hear from composers saying well, they want to be able to give the shape of the music or give the sense of it or the emotion of it, and I think there’s a lot of space to explore in terms of it’s the same sort of thing we’ll want to be able to influence the way any program is going to be, how we’ll be interacting with a program in any field but music is a fun area to play with it.
Ashley Pilipiszyn: Actually, as a followup, if you look at all of our panelists and everything everyone presented too, it’s not just human and AI interaction, but human and AI cooperation. Actually, for anyone who followed our Dota finals event as well, not only did we have a huge success but, and for anyone who is a Dota fan in the crowd, I’d be curious if anyone participated in our co-op challenge. Anyone by chance? No, all right. That’s all right.
Ashley Pilipiszyn: But actually, being able to insert yourself as being on a team with OpenAI Five and I think from all of our research here we’re trying to explore the boundaries of, you know what does human AI cooperation look like and I think that’s going to be a really important question going forward so we’re trying to look at that more.
Speaker: And we have time for two more questions.
Audience Member: Thank you. Just right on time. I have a question for you, Christine. I was at a conference earlier this year and I met this person named Ross Goodwin who wrote using a natural language processing model that he trained a screenplay. I think it’s called Sunspring or something like that. It’s a really silly script that doesn’t make any sense but it’s actually pretty fun to watch. But he mentioned that in the media it’s been mostly–the credit was given to an AI wrote this script and his name was actually never mentioned even though he wrote the model, he got the training data. What is your opinion on authorship in these kinds of tools that … also the one you mentioned where you say you’re actually composing? Are you the composer or is the AI the composer? Should it be like a dual authorship?
Christine Payne: That is a great question. It’s a difficult question that I’ve tried to explore a little bit. I’ve actually tried to talk with lawyers about what is copyright going to look like? Who owns pieces like this? Because in addition to who wrote the model and who’s co-composing or co-writing something, there’s also who’s in the dataset. If your model is imitating someone like are they any part of the author in that?
Christine Payne: Yeah, I mean I have my own sort of guesses of where I think it might go but every time … I think I’m a little bit [inaudible 01:37:11] in terms of the more you think about it, the more you’re like this is a hard problem. It’s really, like if you come down hard on one side or the other because clearly, you don’t want to be able to just press go and have the model just generate a ton of pieces and be like I now own all these pieces. You could just own a ridiculous number of pieces, but if you’re the composer who has carefully worked and crafted the model, crafted … you write a little bit of a piece, you write at some of the piece and then the model writes some and you write some. There’s some interaction that way, then sure, that should be your piece. Yeah, I think it’s something that we probably will see in the near future, law trying to struggle with this but it’s an interesting question. Thanks.
Audience Member: Okay, last question. Oh no.
Ashley Pilipiszyn: We’ll also be around so afterwards you can talk to us.
Audience Member: This is also a followup question and it’s for everyone on the panel. Could you give us some examples of real-life use cases of your research and how that would impact our life?
Ashley Pilipiszyn: An example.
Christine Payne: It’s not an easy one to close on. You want to take it. Go for it.
Lilian Weng: I will say if eventually we can build general purpose robots, just imagine we use the robot to do a lot of dangerous tasks. I mean tasks that might seem danger to humans. That can definitely reduce the risk of human labors or doing repeated work. For example, on assembly line, there are some tasks that involve human hands, but kind of boring. I heard from a friend that there are a lot of churn or there’s a very high churn rate of people who are working on the assembly line, not because it’s low pay or anything, most because it’s very boring and repetitive.
Lilian Weng: It’s not really good for people’s mental health and they have to–like the factory struggle to hire enough people because lots of people will just leave their job after a couple months or half a year. If we can automate all those tasks, we’re definitely going to leave others more interesting and creative position for humans to do and I think that’s going to overall move the productivity of the society. Yeah. That’s still a very far-fetched goal. We’re still working on it.
Amanda Askell: I can also give a faraway thing. I mean I guess my work is,, you know with the direct application, I’m like, “Well, hopefully, ML goes really well.” Ideally, we have a world where all of our institutions are actually both knowledgeable of the work that’s going on in ML and able to react to them really well so a lot of the concerns that people have raised around things like what happens to authorship, what happens to employment, how do you prevent things like the misuse of your model, how can you tell it’s safe? I think if policy work goes really well then ideally, you live in a world where we’ve just made sure that we have all of the kind of right checks in place to make sure that you’re not releasing things that are dangerous or that can be misused or harmful.
Amanda Askell: That just requires a lot of work to ensure that’s the case, both in the ML community, and in law and policy. Ideally, the outcome of great policy work is just all of this goes really smoothly and awesomely and we don’t have any bad things happen. That’s like the really, really modest goal for AI policy work.
Brooke Chan: I had two answers on the short-sighted term, in terms of just AI being applied to video games, AI in video games historically is really awful. It’s either really just bad and scripted and you can beat it easily and you get nothing from it or it’s crazy good because it’s basically cheating at the game and it’s also not really that helpful. Part of what we found out through the Dota project was people actually really did like learning with the AI. When you have an AI that’s at your skill level or slightly above, you have a lot of potential, first of all, to have a really good competitor that you can learn from and work with, but also to be constantly challenged and pushed forward.
Brooke Chan: For a more longer-term perspective, I would leverage off of the robotics work and the stuff that Lilian is doing in terms of the system that we created in order to train our AI is what is more general and can be applied to other sorts of problems. For example, that got utilized a little bit for the robotics project as well and so I feel it’s more open-ended in that sense in terms of the longer-term benefits.
Christine Payne: Okay and I’ll just wrap up saying yeah, I’ve been excited already to see how musicians and composers are using MuseNet. There are a couple examples of performances that have happened now of MuseNet pieces and that’s been really fun to see. The main part that I’m excited about is that I think the model is really good at just coming up with lots and lots of ideas. Even though it’s imitating what the composers might be doing, it opens up possibilities of like, “Oh, I didn’t think that we could actually do this pattern instead.” Moving towards that domain of getting the best of human and the best of models I think is really fun to think about.
Ashley Pilipiszyn: So kind of how I started the event this evening, our three main research areas are really on these capabilities, safety, and policy. You’ve been able to hear that from everyone here. I think the big takeaway and a concrete example I’ll give you is, you think about your own experience going through primary education. You had a teacher and you most likely … you went to science class then you went to math class and then maybe music class and then art class and gym. You had a different teacher and they just assumed, probably for most people, you just assumed you’re all at the same level.
Ashley Pilipiszyn: How I think about it is, we’re working on all these different kind of pieces and components that are able to bring all of these different perspectives together and so a system that you’re able to bring in the math and the music and the gym components of it but also able to understand what level you’re at and personalize that. That’s kind of what I’m really excited about, is this human AI cooperation component and where that’ll take us and help unlock our own capabilities. I think, to quote from Greg Brockman, our CTO, that while all our work is on AI, it’s about the humans. With that, thank you for joining us tonight. We’ll all be around and would love to talk to you more. Thank you.
Speaker: We have a quick update from Christina on our recruiting team.
Ashley Pilipiszyn: Oh, sorry.
Christina Hendrickson: Hey, thanks for coming again tonight. I’m Christina. I work on our recruiting team and just briefly wanted to talk to you about opportunities at OpenAI. If you found the work interesting that you heard about from our amazing speakers tonight and would be interested in exploring the opportunities with us, we are hiring for a number of roles across research, engineering and non-technical positions.
Christina Hendrickson: Quickly going to highlight just a couple of the roles here and then you can check out more on our jobs page. We are hiring a couple roles within software engineering. One of them, or a couple of them are on robotics, so that would be working on the same type of work that Lillian mentioned. We are also hiring on our infrastructure team for software engineers, as well, where you can help us in building some of the world’s largest supercomputing clusters.
Christina Hendrickson: Then the other thing I wanted to highlight is one of our programs. So we are going to have our third class of our scholars program starting in early 2020. We’ll be opening applications for that in a couple weeks so sneak peek on that. What that is, is we’re giving out eight stipends to people who are members of underrepresented groups within engineering so that you can study ML full-time for four months where you’re doing self-study and then you opensource a project.
Christina Hendrickson: Yeah, we’re all super excited to chat with you more. If you’re interested in hearing about that, we have a couple recruiting team members here with us tonight. Can you all stand up, wave? Carson there in the back, Elena here in the front, myself. Carson and I both have iPads if you want to sign up for our mailing list to hear more about opportunities.
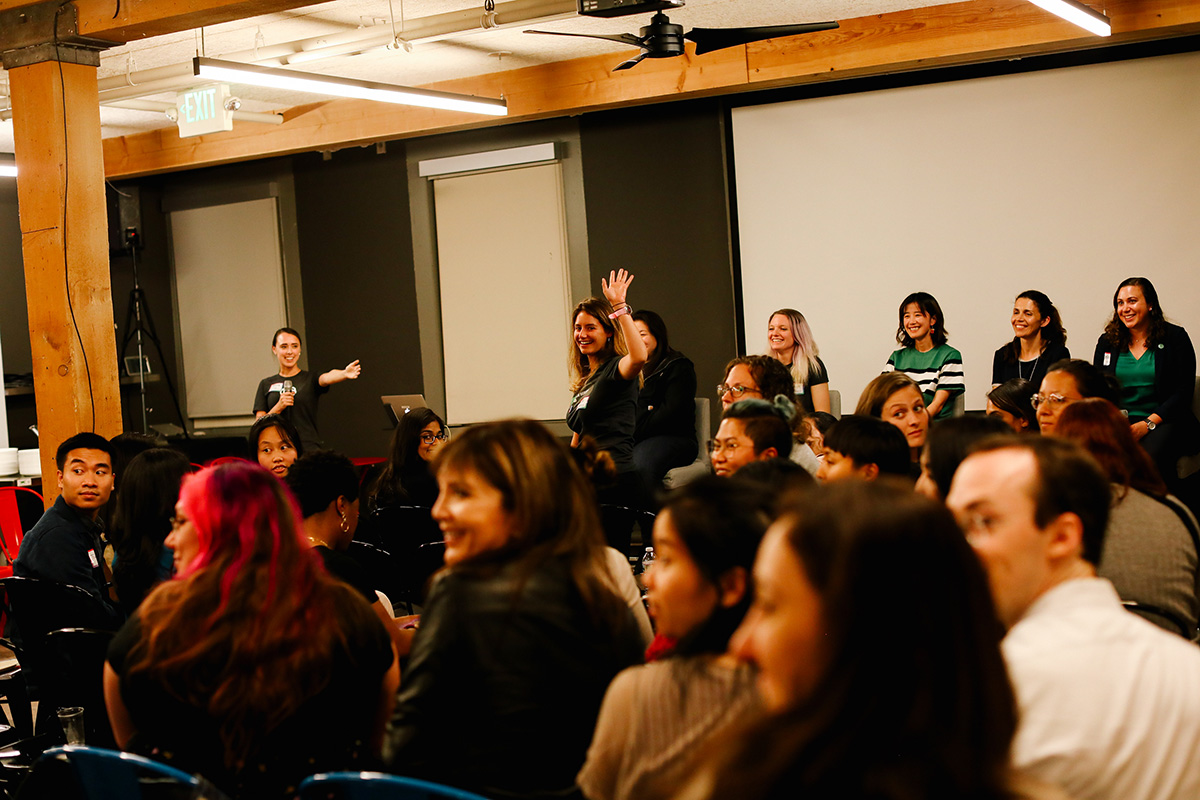
Recruiters Christina Hendrickson and Elena Chatziathanasiadou (waving) make themselves available for conversations after the lightning talks at OpenAI Girl Geek Dinner. Erica Kawamoto Hsu / Girl Geek X
Christina Hendrickson: Thank you all again for coming. Thanks to Girl Geek X. We have Gretchen, Eric, and Erica here today. Thank you to our speakers: Brooke, Amanda, Lilian, Christine, Ashley, and thank you to Frances for helping us in organizing and to all of you for attending.
Ashley Pilipiszyn: Thank you, everybody.
Our mission-aligned Girl Geek X partners are hiring!
- See open jobs at OpenAI and check out open jobs at our trusted partner companies.
- Find more OpenAI Girl Geek Dinner photos – please tag yourselves!
- Does your company want to sponsor a Girl Geek Dinner in 2021? Talk to us!
