VIDEO
Joy Ebertz (Principal Software Engineer at Split) gives an overview of feature flags are, shares interesting use cases around using them to remove debt code load and stress testing, evaluating tech costs, parody testing, and logging.
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- Check out open jobs at our trusted partner companies.
- Watch all ELEVATE 2023 conference video replays!
- Does your company want to sponsor a Girl Geek Dinner? Talk to us!
Angie Chang: With us today, we have Joy Ebertz, who’s a principal software engineer at Split. She leads the backend team from a technical perspective and prior to Split worked at Box for years. In addition to designing software and writing code and running, she writes a blog, which I’ve really enjoyed reading over the years. I’m really excited to welcome Joy here today. Welcome, Joy!
Joy Ebertz: Thank you Angie. Awesome.I’m excited to be here. Today we’re gonna be talking about feature flags. And I know Angie just gave me an amazing introduction, but I’m gonna go through this real fast again. First of all, who am I? As she mentioned, I write a blog on Medium. I like to read, especially fantasy. I like to bake, especially pies, and I like to run especially really long distances on trails. But none of that is why you’re here today.
Joy Ebertz: Who am I professionally? On my blog, I write about running, but I also write a lot about diversity, equity, and inclusion. I write about career topics and I write about tech technical topics. Over the years I’ve worked at a few different places. I was at Microsoft, a really tiny startup. I was at Box and I’m currently at a company called Split.
Joy Ebertz: I’m primarily a backend engineer these days I mostly work in Java. I’ve spent a lot of time splitting monoliths into microservices and thinking about microservice architecture. I’ve also spent a bunch of time over the years working on REST API design and thinking about APIs in general. And I’ve also worked at both Box and Split on authorization and authorization frameworks. And why any of that’s relevant to the topic of feature flags is that Split happens to be a feature flag company. We might happen to think about feature flags a little bit more than the average user out there.
Joy Ebertz: Today I’m gonna be going through just a brief introduction of what are feature flags and then I’m gonna talk through some of the typical use cases we’re gonna go through and then we’re gonna go through some of the more unusual ones. We’re gonna talk about removing dead code load and stress testing, evaluating tech costs, parity testing, and logging.
Joy Ebertz: First of all, what are feature flags? There’s a few other terms you might have heard floating around feature toggles, feature flips, feature switches, conditional feature. And for some really odd reason we happen to call them splits, I don’t know, but basically all of these are different terms to indicate something that is con code, like code branches that’s controlled biographical graphical user interface.
Joy Ebertz: For example, it’s gonna look something like this where you have an if statement that basically just says if the split is turned on, or sorry, if the feature flag is turned on, then you’re gonna do whatever’s in that first block of code, and if not, then you’re gonna do something else. Then on the UI side, you might be able to set it up so that you know, your QA testers get the on treatment, or maybe everybody located in Boston also gets that on treatment. And then everyone else gets the off treatment. And this basically lines up so that then your QA testers and your folks in Boston get routed to that first block of code while everyone else gets that second block of code.
Joy Ebertz: What are some of the typical use cases around these? The biggest one is releasing features. I’m gonna get a little bit more into depth than that one in a second. But the next one is production testing. By this, I just mean you’re able to turn on a new feature or a new fix or something in production for only, like I mentioned before, your QA testers or maybe only the team that’s working on it so they’re able to actually test things on your production environment with your production hardware without impacting all of your users at once A/B/C testing. Being able to test out multiple versions of a website to see what resonates best with your users. And I have the C in there instead of just A/B testing, because sometimes you might have more than two different variations, right?
Joy Ebertz: Like maybe you’re testing a red banner versus a blue banner versus a green banner. That might be an option that you’re doing custom packages. This is basically just being able to give different feature sets to different sets of users. You might have a free set of users and you might have a paid set of users and maybe even have like a business package or an enterprise package. And each of these sets of users have a different feature set that they can see. This is one way to control which users see which features temporary UI customization.
Joy Ebertz: This is one of our, our more interesting features. Basically it’s the ability to actually change things in your UI without changing codes. How this might be used is if, let’s say there’s a storm in Boston, then maybe your customer success folks can update the feature flag to put a banner on the top of the screen that just says expect some delays, thank you for your patience or something, right? And you can then target that to only show up for your customers who are located in Boston. And then I mentioned I was gonna talk a little bit more about releasing features. What are some of the things there?
Joy Ebertz: The first piece is separating deploy from release. Deploy is like the, when you’re actually shipping your code to the cloud, right? It’s when you actually put that code on the servers versus release is when customers start seeing a and how this is useful is because these are both risky, right? And so having them together, it’s really hard to tell which part went wrong if something does go wrong. But by separating them, it makes them both lower risk and it means that you’re able to figure out and quickly roll back from either one if something goes wrong.
Joy Ebertz: The next one is canary or ramped release. Instead of just turning on a feature for all of your users at once, you can slowly roll it out. You can say, first let’s try with the freezer user free users, or maybe we try with 1% of traffic, or maybe we try with a few companies who have agreed to beta test something and then you can get feedback and check your metrics and so on and so forth. And if things look good, then you can increase that until you roll it out to everyone. And I sort of alluded to this already, but it’s also a big off switch. So something does go wrong, it’s very easy to turn that back off and roll back to a known good state. Okay? That’s basic feature flag use cases that are fairly common throughout the industry.
Joy Ebertz: But what are some of the more unusual or advanced use cases? The first one I’m gonna talk about here is using them to remove dead code. First of all, why is your code dead? You might have a method that’s no longer referenced, and I’m sure a few of you’re gonna say, oh, but my IDE can tell me this, right? But maybe you have an endpoint that’s never called, so it’s hard to tell from an IDE with an the actual endpoint, you’re like, your API endpoint is called or not, or maybe you have a parameter input parameter into a method that just never has certain values. Like an if block never gets hit because it just never has that value and these can all stack on top of each other. It might be the case that you have a method that looks like it’s called with certain parameter values, but maybe it never has some of those because the endpoint that would’ve passed those is never called, or maybe the method itself was never called because it’s called from do endpoints, right?
Joy Ebertz: it becomes very, very difficult to tell which pieces of your code are actually in use. One of the obvious ways to do to like try to solve this is to just pepper your code with log statements, right? We at Box, one of our developers actually came up with a lot of this Dave Shepper, but he had a tool that would just go in every branching statement. You add a log line essentially, and it’s just saying this code is not dead. And you have a unique identifier on there so that you can find which actual line was hit later when you’re looking through your logs. The problem with this is since most of us are in software, we know logs are expensive. <Laugh>, especially if you’re peppering all of your code, this is gonna get very, very expensive, right?
Joy Ebertz: One way to solve this is you can wrap the whole thing in a feature flag, right? And then you can just maybe only turn this on for 1% of traffic, right? And then maybe even only leave that on for, let’s say five seconds. And then you can go back to your logs and check which lines of your code were actually hit. And then when you go in there, you can then start sorry. And then you can remove those log lines from your code and then you roll it out to a little bit more and then remove more log lines and eventually any of those log lines that are still in your code are probably not in use anymore. And so you can roll it out to a hundred percent and leave it there as long as it makes you comfortable. For most of the features that we have, this is, you know, probably a couple of weeks maybe a month at most.
Joy Ebertz: When I was at Box, at one point we were working on some authorization code and looking at removing some of that and we were permissions, people get touchy about permission, so we actually left that one on for, I wanna say a year because we weren’t quite comfortable removing it until then. But anyway, once you’re comfortable, then at that point you can assume any of those log lines that are still not showing up in your logs are not being hit anywhere and you can go ahead and remove that entire code block.
Joy Ebertz: Okay, next, use case load and stress testing. I know a lot of, you’re probably familiar with tools such as Gatling or JMeter, and these tools are great. They allow you to basically write a set of test cases and run them repeatedly at like higher and higher rates against your systems, and this is a great way to tell or to load and stress tests. sorry, back up a second.
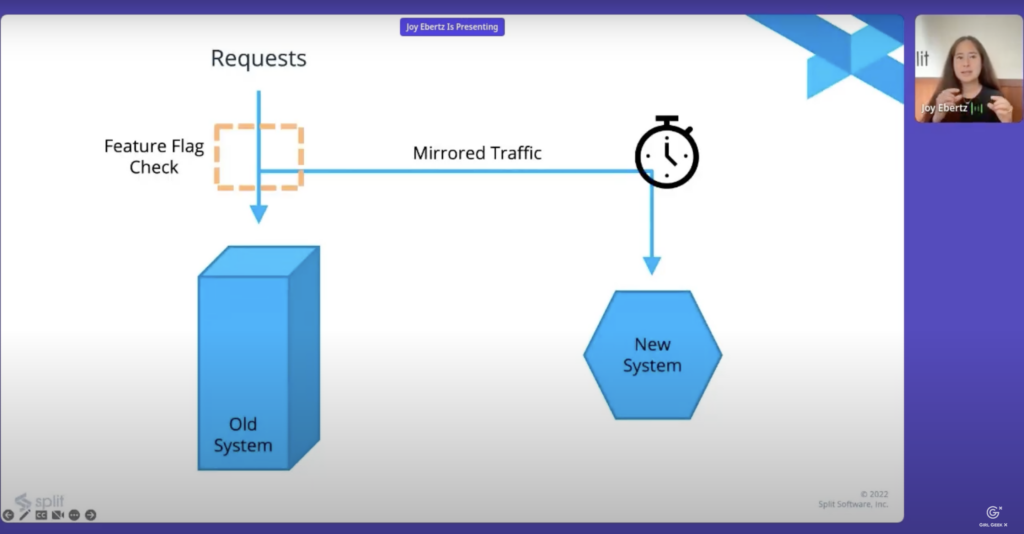
Joy Ebertz: Load testing is making sure that a new system can handle expected load. Stress testing is trying to figure out the point where that new system falls over. As you might be able to see by sending a bunch of test requests to a system, you can do both of these things. However, the big problem with those is you’re relying on a set of test cases written by a developer and it usually doesn’t reflect actual traffic patterns that you might be receiving through your site. Even if it does, you’re probably gonna have to spend a lot of time in order to get those realistic traffic patterns. One thing you can do instead is actually mirror your traffic and that basically means that you send your traffic like normal to your existing system and at the same time you send an asynchronous request over to the new system.
Joy Ebertz: And what’s nice here is that as I’ve kind of indicated with the arrow, you can start with that ramping like we talked about before. Initially you can just send 1% of your traffic to the new system and then slowly ramp it up. And what’s nice about this is then if your system new system does fall over, it’s much easier to see exactly at what point it fall over. And at least in my experience, it’s often much easier to debug what went wrong if you’re right at that inflection point rather than way over it. A lot of times when you’re way over, everything’s blowing up, everything’s falling over and it’s really hard to tell what the initial problem was. This allows you to find that exact point when things went wrong. And then stress testing. If you wanna go beyond your current traffic patterns, you might be able to start or you can start sending the same request multiple times to the new system.
Joy Ebertz: Maybe you sent it once and then you wait five seconds and you send it again. And this will allow you to send more traffic to the new system than you’re actually accepting your old system. And I fully admit that this is not quite realistic either, since you’re like, resending requests isn’t something that happens all the time with traffic, but it should still hopefully help with a slightly more realistic traffic pattern than you’re gonna be able to come up with in tests without a lot of time spent on those tests. Okay, that was load and stress testing. Next we’re gonna talk about evaluating tech costs. As you might have predicted, this is a very similar setup to that last one. The key for this one though is again, with the mirrored traffic, instead we’re going to just turn it on for a very specific length of time.
Joy Ebertz: Depending on what your traffic patterns normally look like, you’re just gonna pick something that’s representative. Maybe this is a week, maybe this is a day if your days look fairly similar – every site’s a little different, right? But the idea here then is, once you’ve figured out how much it’s gonna cost for that representative period, you can go ahead and then just extrapolate from there, and calculate what you think it will cost for the year, for example. One thing with this one, we’ve actually done this a few times at Split, you might wanna do it more the POC side of things. We’ve done this a couple times just as a, like, we’re considering this new technology, we have no idea if it’s a good idea, we’re just gonna like kind of gut check and you know, with a POC try to figure out what it might look like.
Joy Ebertz: But we’ve also done this… one of our more recent ones, we did this actually in pretty late stage. We were cleaning up an entire data pipeline system, replacing with something entirely new, and like we were pretty sure we wanted to go with this new thing, but we wanted to make sure we wanted this like last validation before we really started doing things. They weren’t going to completely blow the budget outta the water, right? It was a nice gut check at the end to make sure we were in the realm that we expected to be in.
Joy Ebertz: The next use case I wanna talk about is verifying parody or parody testing. This is also sometimes called tap compare testing and this is pretty similar. The other ones one of the key differences, while it doesn’t matter for the other ones, when you send the mirrored request. For this one, you wanna wait until you already have the response from your old system. And this is useful because then we’re gonna go ahead and send the request again to the new system, but we’re gonna compare the responses from these two systems to each other. And if they’re different, then we’re gonna go ahead and log it.
Joy Ebertz: And where the feature flag is useful is, again, because logs are expensive, right? We don’t wanna be spamming our logs and especially if something does go wrong, then we can go ahead and turn off the logging while we try to debug and figure out what happened or maybe turn it on just for a particular user while we try to debug exactly what’s causing the difference, while all other traffic continue can continue to flow to the new system to continue to load test it, but maybe not parody test it anymore. And this is one that we’ve used a few times at Box, when we use this, it was for our authorization system, we were replacing part of that, and we actually discovered that we had forgotten an entire feature, like an entire feature was something that somehow nobody noticed was missing.
Joy Ebertz: But because we had done this parody test, we caught it before this was the new system was rolled out to a single user, so we impacted zero users in the process, but we were able to find that we had a problem here. Another use case we had at Split recently is we were replacing a database with a completely different data system and it aas a nice way to ensure that the data coming out of the new database matched what was in the old one after we had migrated everything and done all of the various other pieces, it was nice to be able to verify that yes, the new data does match our old data and everything makes sense.
Joy Ebertz: Okay, last use case. Controlling logging. I kind of touched on this before, but logging is expensive. There’s this like tension between, do you log a lot and pay a lot of money versus do you log not very much and then when you know a problem happens, you’re totally in trouble, right? Like you don’t really wanna be in either of these situations, right? It’s kind of a problem in both cases, <laugh>.
Joy Ebertz: One way that a lot of people solve this is by basically, trying to reduce your logs, but then have a way to be able to through configuration, turn them on if things are going badly. And specifically, one way you can do this is through a feature flag. And I guess we’re currently working on doing some of this. We’re adding a library, like a wrapper library on top of the logging, which does a number of different things. But among the other things that it does is it enables us to put a single feature flag into that library that we’re adding. And this is nice because it allows us to quickly turn on and off the logging without having to push actual configuration in order to change those logging levels. And these are just to kind of give an idea of why that’s useful.
Joy Ebertz: In order to change the feature flag, and this is assuming that like maybe I need to get an approval on it and like, people aren’t quite instantly there. Like let’s say it takes 15 seconds in order for me to make a change and somebody else to come in and improve it versus this was one of our recent runs. It took 26 minutes of pipeline to get a change from, developer merged into our staging environment and then another six minutes to deploy that to production. And granted, an emergency situation, you might be able to bypass a few of those things in there, but we’re still talking on the order of seconds versus the order of minutes. And that can really matter when you’re talking about downtime or you’re talking about a real issue.
Joy Ebertz: The other nice thing about this is because it’s a feature flag, you can start to do more fine grain control too. So if you know that the issue is only affecting certain types of users or certain organizations, you’re able to then basically target only those people or only those organizations, which allows you, again, to limit the number of logs that you’re storing. But at the same time you know, you’re going to be able to get the information that you need or it might other be, might be other information maybe it’s certain profile types.
Joy Ebertz: Maybe it’s only affecting people in Boston which you can again use. Or it might even be that you happen to know that the problem is likely in the stack trace. So maybe you want to just log things from that stack trace and ignore all of the other, all of the other information out there. It’s also possible to do not just based on the user and the request, but also based on the actual classes and that side of things as well. So which, which pieces of code are you increasing the logging for? Awesome.
Joy Ebertz: This was a whirlwind trip through feature flags. Just a quick recap. I covered what feature flags are some of the typical use cases and then I went into some more interesting use cases around using them to remove debt code load and stress testing, evaluating tech costs, parody testing, and logging. I’m out of time actually, so if you have any questions you can go ahead and email me, or this is my blog as well.
Angie Chang: Thank, thank you, joy. That was excellent. I, like I said, I love Joy’s blog. I ever highly recommend to read it for both career and technical advice. And the feature flags topic has been always – I always see it on Twitter – so I’m really glad that this talk helped educate me on what it is. Thank you again, Joy.
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- Check out open jobs at our trusted partner companies.
- Watch all ELEVATE 2023 conference video replays!
- Does your company want to sponsor a Girl Geek Dinner? Talk to us!
