VIDEO
Xinran Waibel (Senior Data Engineer at Netflix) talks about modern data engineering, how data quality is defined and measured, and why it’s important for data engineering to closely connect with business. She will discuss challenges and practical tips on designing data systems that consistently produce high-quality data.
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- Check out open jobs at our trusted partner companies.
- Watch all ELEVATE 2023 conference video replays!
- Does your company want to sponsor a Girl Geek Dinner? Talk to us!

Sukrutha Bhadouria: Up next we have Xinran, who’s a senior software engineer at Netflix. She’s on the personalization data engineering team, building data applications to power ML algorithms and product innovation. Before Netflix, she worked at Confluent and Target as a data engineer. She founded a publication dedicated to data engineering called “Data Engineering Things” and writes regularly. Welcome.
Xinran Waibel: Yes, thank you for the introduction. Hi everyone. My name is Xinran Waibel and I’m a senior data engineer at Netflix. And today I’ll talk to you about how to engineer data for better data quality. And I personally love emojis, so if you see anything in my presentation you love, bring out all the emojis, <laugh>, I love them.
Xinran Waibel: Let’s get started. And so here’s agenda for today. I’ll first tell you a little bit about myself, and for those of you who sound familiar with data engineering, I’ll give you a summary of what the engineering is.
Xinran Waibel: And since we’re gonna spend the whole time talking about data quality, I’ll talk about why the quality should be the bottom line of any data engineering system, how to define data quality, how to monitor data quality as part of your data system. And at the end, I prepare a sweet summary of the best practice that you can use to ensure high data quality in your data system.
Xinran Waibel: First of all, little bit about myself. My name is Xinran. I know this, the name is kind of hard pronounce, but the trick is that the X is pronounced like “sh” and I have been working this engineering for about six years now, and then I’m still having a lot of fun loving it, and I always tell other people that being an engineer, like I get to solve Data Apollos every day and it’s very rewarding. And right now, so I’m a member of personalization data engineering team at Netflix and my team build various different data system that feed data into our personalization data algorithms.
Xinran Waibel: I also personally really like writing about data engineering too. I created this publication called “Data Engineer Things”, some Mediums, and then I write blogs every once in a while to share my learnings of what I learn at work. And I hope you check it out later after the presentation. And in my personal life, I’m a dog mom. Here’s a picture of me and Foxy. We spend a lot of time together and and also I love pottery. I just learned to do ceramic last year and then absolutely loving it. Actually this year I just set up a small pottery studio in my garage and I’m very excited to do most pottery at home. So get to the technical topic.
Xinran Waibel: What is data engineering? And if you search about data engineering online, you might see so many different keywords that you see here is about building data pipelines, data plumbers, data cleaning, and the ETL, ELT, and you might learn about batch and streaming and frameworks like Kafka and Spark. But what is data engineering like?
Xinran Waibel: From my perspective, like all of this is all part of data engineering. However, it is only describing data engineering from a specific angle. And here’s what data engineering is in my own eyes.
Xinran Waibel: For me, data engineering is all about making data accessible in optimized formats. When I say optimized formats, the data is enriched with business logic and metadata, so it can be easily used to solve business problems. And data is also stored in efficient data schema and storage system, so if your downstream user are going to process this data further, they can get great performance in their data processing too. And last but not least, data should be available within the desirable latency because there’s some data you would get more value when you build up a significant amount of history, but also their datas would lose its value as the delay goes up.
Xinran Waibel: You might need to build a data system that’s runs daily or hourly or you streaming system that process the event as it comes in. And most importantly, all the data engineering system should provide data in high quality. And I believe that is the bottom line of any data engineering system.
Xinran Waibel: So why is data quality so important? The main reason is because the outcome of data engineering system is used to derive data insights. Whether it is used to generate some metrics dashboard for executives, or it is used to directly power some product feature, or it is used as input data to your machine learning algorithms, and any data insights can only be as good as the source data. As you can imagine, if your data engineering system is producing incorrect data, any of the decision made based on those data will be at risk as well.

Xinran Waibel: This stock meme here, I love it, and it perfectly summarized that why I want to give a 20 minutes presentation today on data quality itself because I’ve seen so many data systems in the past, including the one I built myself that don’t have data quality check, and the data engineers don’t even know when the data systems are not running correctly or producing incorrect data. And at the same time, important decisions are being made based on those data, and that is a very dangerous situation that you don’t want to be in.
Xinran Waibel: Now that we’re all on the same page about why data quality is important, let’s talk about how to define and measure data quality. Defining data quality is not an easy task at all. The first and also the most important step before you define the data quality is that you have to know your data.
Xinran Waibel: Ask yourself these three questions, what does my data represent? How is my data being used by downstream users, and what could possibly go wrong? And for any data engineer to answer those questions, I believe business context is really critical because you have to understand the business problem first before you build your data system, and of course, before your design data quality for a few reasons. The business model determines the nature of the data and for example, how your business works is directly associated with the data that’s getting produced. For example, what is the relation of account and the profile that is directed, that was directly impacted by how user can create account in the profile when they use your product.
Xinran Waibel: And another example is that, business model also determines the traffic pattern that you might observe in your data. Let’s take Netflix for example. If you work for a company who’s based on it is about entertainment like Netflix, then you might have more traffic during holiday and weekend, versus on weekend or on weekdays. However, if you work for a software company who builds software for business users, then you might have more traffic during weekdays versus on holiday. And also, business contacts help you spot the potential edge cases too. Let’s say, if you work with playback data on Netflix and you will think about, hey, how will my data surface edge cases like where the user tried to start a playback but then didn’t start, how would you spot / identify those cases in your data and how do you want to deal with it as part of your system?
Xinran Waibel: And because any data engineering system is built at the beginning to solve specific data business problem, in a way, the downstream use cases actually define the expectation of your data. And also that means that the definition of your data quality is only valid for the use cases in mind. And those sounds might sound kind of conceptual but let me give you an example because the data quality itself is a very subjective matter, it’s really depending on how you expect the data to be used and who’s using it. Let’s take Netflix for example. Let’s say you are building a dimension table that represents a Netflix movie, and then you have a category field. For when you talk about category, and it might mean different things. When we talk to different departments, it could mean the category that we surface on to our product for user to select, to explore movies, or if you’re talking about category on the content side, it’s a different category when it comes to content production.
Xinran Waibel: Let’s say if you build this data set for product use cases, then your data quality will be at risk if you start surfacing the production category in your data set. So that is an example how data quality is relative to the use cases. For this, engineers, my recommendation is always that if you ever feels like you don’t understand your data well, I recommend you always talk to other teams, your business partners, so that you get more business context and understand how the business is associated with your data.
Xinran Waibel: Assuming that you have a good understanding of a comprehensive understanding of your data, now it’s important to establish some clear expectation for your data first, and also tolerance, because no data is perfect. For example, the column should only have values and meeting certain criteria. And you know, for example, the membership tab should only be basic or premium, and data should somewhat align with historical value. For example, the number of accounts that you see today should be very close to yesterday.
Xinran Waibel: Another thing you could also set is that the data should be somewhat aligned with another data set. Let’s say you have a data system that process input data and then does approximate one to one mapping, then you can expect the output is relatively aligned with the input as well. And from <inaudible> perspective, we can expect data to be you know, available within certain latency. Let’s say if you have a daily workflow, then you can, you know, have the expectation that daily job should finish before Pacific AM every day. This is some of the very basic expectation we would have on data set, but also depending on the data and the data system, you might want to add more to the list that’s more complicated.
Xinran Waibel: Now that you have a clear set expectation of your data, the next step is to compute data quality metrics that help you qualify the deviation of the extra data from your expectation, and then you can compare the deviation with your tolerance, to see whether the data quality is up to your bar. Here are some of the examples. You can compute the percentage of playback events when the membership ID is invalid, or you can check the the number playback today, assuming today is Thursday, and compare to previous Thursday average.
Xinran Waibel: I really love this example here because it gives you the idea of that how you can kind of incorporate the traffic pattern that you are aware of, data to your audit so that you can audit on your data quality more effectively. And another example is that you can calculate the percentage playback events, but only those with membership tabs basic and compare it to the seven day average. This is also a great example that how you can add more dimension and breakdown to your database, based on your best understanding of data to ensure that data quality is is high. And another, from a SLA perspective, you can measure the end-to-end runtime of your job and making sure that it meets the SLA of your downstream user. There are so many possible data quality checks you can have in place and you might be wondering, oh my god, what, how much, how many is enough?
Xinran Waibel: I mean, honestly there’s no right answer. However, my personal rule of some is that, you know, with this list of data quality check I have in place, if they all passed, I can confidently say for sure that I know my data is all good. That is the principle I really use when I designed data quality checks.
Xinran Waibel: Next section: monitoring data quality. This section is important because data quality check isn’t a one time task. You know, beyond all the unit task and integration, task integration task you’ll have as part of the development process, you also want to monitor your data quality continuously as part of your data system, so you can keep track of your data quality as your business and data evolve. And this, this section, I’ll talk a little bit more about how exactly we do that.
Xinran Waibel: The methodology of integrating data quality checks in your system is a little bit different for batch and streaming system. In the batch world, we typically use this pattern called Write-Audit-Publish. The first step is that you run your batch shop red output to a temporary location, then you run your data audit check against those output if it passed, then you publish your data to the permanent location. And as you can see from the screenshot here that when the data audit didn’t pass then it will send, actually send the pager to our on-call and on-call will intervene and investigate If everything’s good, then they will manually unblock it, but if it doesn’t, they’ll reach out to other teams to investigate further. That is the Write-Audit-Publish pattern that we typically use for batch pipeline.
Xinran Waibel: In the streaming world it’s a little bit different. In for event streaming job, we would typically alert based on some of the realtime metrics we collect from application. It would include some of the job health metrics, for example, the number of jobs that’s running of the consumer like watermark, making sure that the the job is making progress / is not left in behind, and also we also have a lot of custom per event metrics we capture as part of the data processing logic as well. Like for example, the number of events are filtered in or out, the number of parts fit we’re getting, the number records with in invalid fields, and also the output volume. Those are just the, some of the simple examples you could do.
Xinran Waibel: And another thing I want to mention here is that because this stage is actually really common to write the output of your event streaming job to a table, you can also use the right audit published pattern on your streaming output as well. The only difference is that it is the delay that introduced because you are running your audit at theoretical manner as part of a scheduled batch shop.
Xinran Waibel: Assuming that you are responsible data engineer, you know your data well, you also set up all this great data quality check as part of your system, what could possibly go wrong from here? And this is another scenario you could be in that you have so many data audits, that’s firing alerts all the time, and some of them may not be reflecting your real issue. You don’t even know which fire is real, which fire isn’t. And that puts your team in a lot of on-call burden and also just operational cost as well. And that leads to the next section – the common challenges of maintaining data qualities in production.
Xinran Waibel: One of the common challenges as I showed in the previous stock meme is that you might have a lot of data audit that’s very noisy and the noisy one might distract you from the real data quality issue. For example, it might be because that you have too low a threshold and or because that you totally ignored the organic traffic pattern as your data quality so you’re basically alerting based on the organic traffic pattern that’s expected. The recommendation here is always revisit your data theoretically to see which one need to be tuned so that it can be more accurate and not producing unnecessary noise.
Xinran Waibel: Another challenge here that sometimes data orders don’t get updated as you update the business logic as part of your job. You know, like we talk about before, data quality is relative to the business problem you are solving so that whenever you update the business logic as part of your system, you should also revisit your data alerts so that your data quality check is up to date as well.
Xinran Waibel: Next one. You know, that one is also really painful that because you don’t log enough information as part of your system and also your logging, it’s very difficult to troubleshoot failures. This will actually apply to both batch and the streaming world because a lot of times, we might see a realtime metric saying, oh hey, like we have a spike of passing failures. However, it doesn’t log enough information about the event the identifier of the event. It’s really hard to go back to troubleshoot what event get jobs for what reason, and similarly for the batch world, a good example is that if you have a Spark job that have 20 filter on the source data and the the data, all the data might get dropped because that one filter, but it could be really hard for you to figure out which is that filter that is causing the problem.
Xinran Waibel: And that is all because of like logging or intermediate data you are producing, so just be mindful about what data you should log or intermediate data you should pro produce so that’s easier for your oncall and yourself to troubleshoot the issue when it comes.
Xinran Waibel: Another common challenge, which is actually problem that my team deal with a lot is that a lot of times your data, all this fire ,not because something went wrong with your data system, actually, it has to do with upstream data changes. It’s very common that in some of the data systems that you build your data system based on some assumption of your source data ,and therefore there’s certain type of data contract there between you and your source system. However, because when those data contract is not enforced through some programmatic matters such as like, integration test, then it could be broken all the time and then you catch those issues in your data system instead and then you have to go back and forth with the upstream team to fix them.
Xinran Waibel: in this case, it is really important that you enforce the data contract with your upstream through some programmatic mess methods so that it’s less likely you know, for upstream to introduce unexpected data updates.
Xinran Waibel: Another problem that’s probably applies everywhere is that, people come and goes and they might not have enough documentation on the data quality check and you might not know why data quality, certain data quality checks there, and when it fails you don’t know what to do. It’s always the best practice to add enough documentation for data quality, and the why that that exists, and what to do when that fail.
Xinran Waibel: Another one but this is very interesting one because we don’t run into this very often, but it’s also quite interesting problem, is that when we build data all this, a lot of times we would explore the data based on the historical data already available and then that can help us understand the data a little bit better and set some tolerance. However, if you are building a data system for a completely new product, you will have no historical data to refer to, so it could be very difficult to set data quality check and the tolerance you have. In this case honestly I don’t have any really good ideas, but I think the best thing you can do is just keep a close eye on your new data pipeline and this data get getting produced because as part of the new service and then revisit the data audit maybe after a week or months after it’s released, so that you should just have to keep an eye on it.
Xinran Waibel: Another really important thing I wanna cover at the end is about data recovery. Because no data is perfect, so you are going to eventually have a lot of fail data, all this that is gonna tell you, hey, like there’s some serious issues, system is producing incorrect data and what could you do? And sometimes, you might be able to fix it very easily, however you, if the data is already produced and you have to have some backup method to re backfill the data, to mitigate downstream impact. And then the methodology for data recovery is actually different for batch versus event streaming system.
Xinran Waibel: In a batch world, it’s pretty much guaranteed that all of your system will be back fillable because you know, you are, you are reading from data from a location where the data have really long retention and then you could just simulate / rerun your batch job and then also ask your downstream to rerun, and then you just basically do this over right, the partition and the data could be fixed.
Xinran Waibel: However, in the streaming world, not all system is by default backfillable. That is mainly because the source of the data you already have very limited retention. In most cases, that is a Kafka Topic and it’s very expensive to have very long retention for your Kafka data if your data size is really huge.
Xinran Waibel: There’s some options for backfeeding streaming job here. I’ll just like give you guys a quick summary, but <inaudible> talk about this for an hour if I want to. Yeah.
Sukrutha Bhadouria: Can we Xinran, can we, can we wrap this up now? We have people in the next session ready?
Xinran Waibel: Yeah. Can we, yeah, definitely. You know there’s also options for backfilling, but then my recommendation that you should always have you know, some backfilling options in mind when the data outage happens.
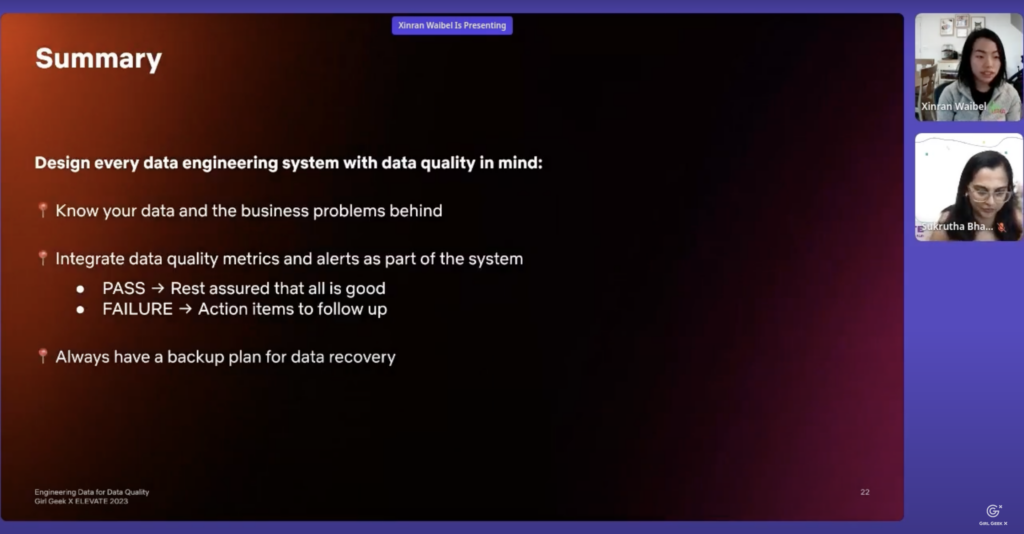
Xinran Waibel: Just a quick summary of the best practice I have in mind for data quality. First of all, you want to design every data engineering system with data quality in mind. You must know your data and business problem well, and then you want to integrate your data quality metrics and alerts as part of the system. That means that when they pass, you can reassure that knowing that now is good, but also in fail you should have clear action item to follow up with. Last but not least, you should always have a backup plan for data recovery so that when the outage happens, you have a way to mitigate downstream impact.
Xinran Waibel: Sorry for running out of time. That’s everything I wanna cover for today. Feel free to find me on LinkedIn to connect with me. And if you want to learn more about data engineering, check out the “Data Engineering Things” Medium.
Sukrutha Bhadouria: Thank you, Xinran, this was wonderful. See you in the next session.
Xinran Waibel: Right.
Like what you see here? Our mission-aligned Girl Geek X partners are hiring!
- Check out open jobs at our trusted partner companies.
- Watch all ELEVATE 2023 conference video replays!
- Does your company want to sponsor a Girl Geek Dinner? Talk to us!
